
写文章




- @qq_57390446
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
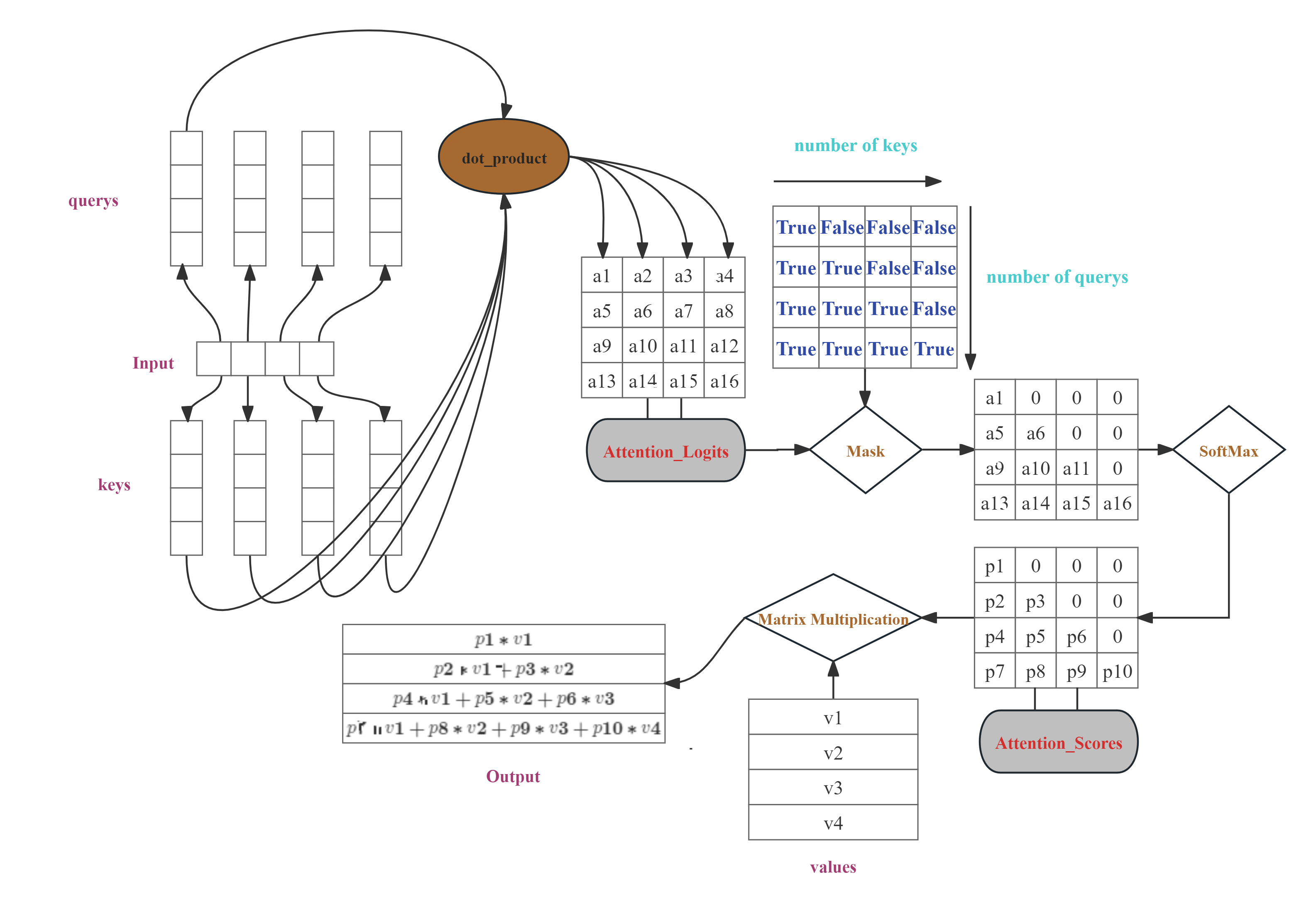
Causal Attention的底层原理
Transformer的Decoder中最显著的结构是Casual Attention。通过本篇文章,你将学会Casual Attention的机制原理;Casual Attention在TensorFlow中的实现原理;如何快速地保存并打印TensorFlow中模型已经训练好的参数;如何实现Transformer的Decoder的前向传播;
基于SOLA算法的变声实例
SOLA算法背景下的变声器(附有源码和源码分析以及原理分析与SOLA算法精讲)——实现声音的变调不变速或者变速。
中文评论情感分类——RNN模型
利用TensorFlow训练一个中文文本情感二分类的RNN模型,涉及了LSTM算法

BertTokenizer详解
英语文本的预处理通常是Tonkenizing,而Tonkenizing的最小维度分为三种——word(单词),wordpiece(单词块),character(字母)。word的Tokenizing很好处理,因为英文文本单词之间有着天然的空格符,完全可以根据空格符进行Tokenizing。character的Tokenizing也同样好处理,只需将文本里所有字母切分开就行了。但是wordpiece
Springboot接受文件与发送文件
前后端涉及到文件的传输,都是以二进制流的形式进行交互的。
到底了