- @qq_55796594
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1.Anaconda和python的关系Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等。Anaconda可以视为python的一个发行版,是针对机器学习和数据科学的一个特殊的python版。硬要类比的话,如果python是初始的安卓系统,那么Anaconda就是内置了安全管家、聊天软件等实用工具后的安卓系统。那么Anaconda在机器学习方面
1.数据处理1.1标号数据读取1.1.1数据集划分安全帽数据集共有5000张图片和5000个标注文件xml,每个xml文件对应一张图片,在提取数据集的标号前,首先应该划分数据集train、test、val各3750、625、625张,分别占全部数据集的1/4、1/8、1/8。# 数据预处理:5000张图片和5000个标注xml文件# 划分集合:train:3750, test:625, val:6
1.Anaconda和python的关系Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等。Anaconda可以视为python的一个发行版,是针对机器学习和数据科学的一个特殊的python版。硬要类比的话,如果python是初始的安卓系统,那么Anaconda就是内置了安全管家、聊天软件等实用工具后的安卓系统。那么Anaconda在机器学习方面
1.数据处理1.1标号数据读取1.1.1数据集划分安全帽数据集共有5000张图片和5000个标注文件xml,每个xml文件对应一张图片,在提取数据集的标号前,首先应该划分数据集train、test、val各3750、625、625张,分别占全部数据集的1/4、1/8、1/8。# 数据预处理:5000张图片和5000个标注xml文件# 划分集合:train:3750, test:625, val:6
尝试用python做音频的LSB隐藏算法,过程是曲折的,虽然结果还有一些瑕疵,毕竟对音频的信号处理还不太熟练,不过结果总算是成功了。1.环境win10操作系统、pycharm编辑器、python3.9、第三方库:librosa、bitarray1.1安装bitarray之所以选择安装bitarray是为了解决中英文字符串和二进制字符串的转化问题pip install bitarray1.2安装li
1.API分类1.1基础API对于训练调优场景,使用paddle.save/load保存和载入模型。对于推理部署场景,使用paddle.jit.save/load(动态图)和paddle.static.save/load_inference_model(静态图)保存载入模型。1.2高级APIpaddle.Model.fit (训练接口,同时带有参数保存的功能)paddle.Model.savepa

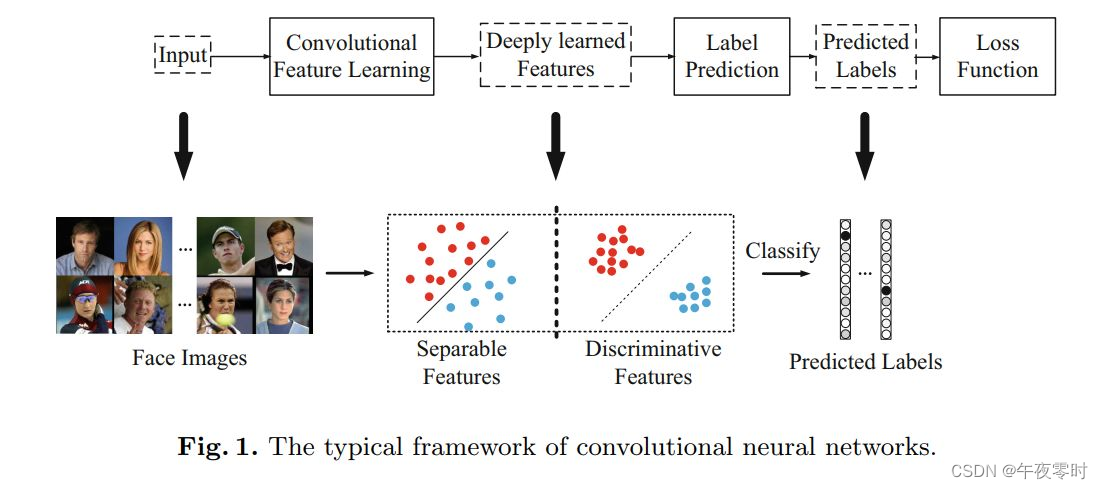
ArcFace/InsightFace(弧度)是伦敦帝国理工学院邓建康等在2018.01发表,在SphereFace基础上改进了对特征向量归一化和加性角度间隔,提高了类间可分性同时加强类内紧度和类间差异。论文链接:ArcFace: Additive Angular Margin Loss for Deep Face RecognitionLFW上99.83%,YTF上98.02%作为基于 soft