




- @qq_52771580
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:针对基于RoPE的大模型在长文本输入时存在的位置外推缺陷,论文提出位置插值(PI)方法,通过线性缩放位置索引将超长序列映射到预训练范围内,仅需少量微调即可扩展上下文窗口。PI无需修改模型架构或新增参数,实验表明其能有效提升模型在长文本任务中的表现,成为轻量化扩展大模型上下文的主流方案。该方案实现简单、兼容性强,为后续优化提供了基础思路。
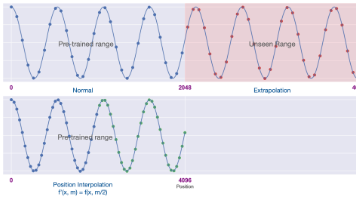
摘要:针对基于RoPE的大模型在长文本输入时存在的位置外推缺陷,论文提出位置插值(PI)方法,通过线性缩放位置索引将超长序列映射到预训练范围内,仅需少量微调即可扩展上下文窗口。PI无需修改模型架构或新增参数,实验表明其能有效提升模型在长文本任务中的表现,成为轻量化扩展大模型上下文的主流方案。该方案实现简单、兼容性强,为后续优化提供了基础思路。
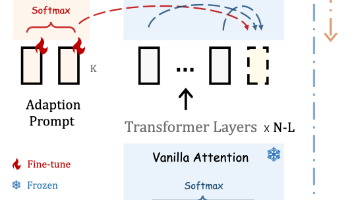
《LLaMA-Adapter:基于零初始注意力的高效语言模型微调方法》提出了一种轻量级大模型微调方案,通过引入可学习的Adaption Prompts和创新的Zero-Initialized Attention机制,有效解决了传统微调方法的高计算成本和灾难性遗忘问题。该方法仅需训练少量参数即可实现下游任务适配,并通过零初始化门控因子逐步注入任务知识,保持预训练模型的核心能力。此外,LLaMA-Ad
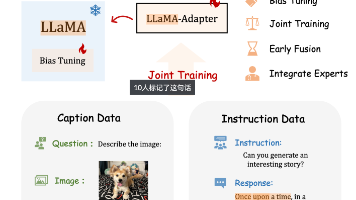
本文系统介绍了LLaMA-AdapterV2的技术创新,这是一种针对LLM的高效轻量化微调方法。该模型在初代LLaMA-Adapter基础上进行了三大关键改进:(1)引入可学习偏置项与缩放因子,增强模型表达能力;(2)采用参数分离训练策略,有效协调多模态理解与指令跟随任务;(3)实施视觉信息早期融合方案,避免跨模态干扰。此外,通过整合外部专家系统弥补视觉推理短板。这些优化仅增加0.04%参数量(约
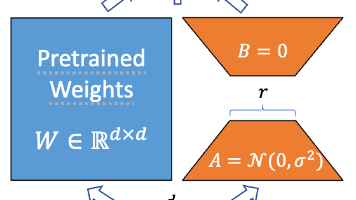
本文系统介绍了大模型微调方法LoRA的原理与应用。针对全参数微调的高成本问题,LoRA通过冻结预训练模型权重,仅训练低秩矩阵分解的小参数分支,实现高效迁移学习。其核心优势包括:低算力需求、效果媲美全量微调、模块化设计。技术实现上,LoRA在注意力层等线性变换旁添加低秩矩阵(A/B矩阵),通过矩阵分解将参数量从d×k降至2dr。当前已广泛应用于垂直领域定制(医疗/法律等)、个性化对话、多模态适配、安
本文系统介绍了LLaMA-AdapterV2的技术创新,这是一种针对LLM的高效轻量化微调方法。该模型在初代LLaMA-Adapter基础上进行了三大关键改进:(1)引入可学习偏置项与缩放因子,增强模型表达能力;(2)采用参数分离训练策略,有效协调多模态理解与指令跟随任务;(3)实施视觉信息早期融合方案,避免跨模态干扰。此外,通过整合外部专家系统弥补视觉推理短板。这些优化仅增加0.04%参数量(约
《LLaMA-Adapter:基于零初始注意力的高效语言模型微调方法》提出了一种轻量级大模型微调方案,通过引入可学习的Adaption Prompts和创新的Zero-Initialized Attention机制,有效解决了传统微调方法的高计算成本和灾难性遗忘问题。该方法仅需训练少量参数即可实现下游任务适配,并通过零初始化门控因子逐步注入任务知识,保持预训练模型的核心能力。此外,LLaMA-Ad
如何将AHA数据库中.txt文件转换为WFDB格式
cv2库的库名是opencv-python,可使用豆瓣源快速安装:pip3 install opencv-python -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com若网速比较快可以直接执行以下命令安装:pip install opencv-python