




- @qq_46644077
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
对于大模型初学者来说,本地部署的第一步不一定是直接追求最大、最强的模型,而是先把完整流程跑通。qwen3.5:4b这是 Qwen3.5 系列的 4B 多模态模型,支持文本和图像输入,适合用来学习本地多模态大模型部署。Ollama 可以简单理解为一个本地大模型运行器。它不是模型本身,而是负责模型下载、模型管理、本地推理和 API 服务。

对于大模型初学者来说,本地部署的第一步不一定是直接追求最大、最强的模型,而是先把完整流程跑通。qwen3.5:4b这是 Qwen3.5 系列的 4B 多模态模型,支持文本和图像输入,适合用来学习本地多模态大模型部署。Ollama 可以简单理解为一个本地大模型运行器。它不是模型本身,而是负责模型下载、模型管理、本地推理和 API 服务。
RS Prelabel Studio 的核心目标是将开放词汇遥感语义分割和语义变化检测能力整理成一个更加易用的预标注工具。模型生成初始结果,人工进行核查和修订。对于遥感语义分割、变化检测、建筑变化检测和样本预标注任务,这类流程可以在一定程度上降低人工标注成本,也有助于把科研模型更自然地接入实际工程应用。欢迎对遥感智能解译、语义变化检测、开放词汇分割或样本预标注感兴趣的朋友关注项目。如果觉得这个项目

对于大模型初学者来说,本地部署的第一步不一定是直接追求最大、最强的模型,而是先把完整流程跑通。qwen3.5:4b这是 Qwen3.5 系列的 4B 多模态模型,支持文本和图像输入,适合用来学习本地多模态大模型部署。Ollama 可以简单理解为一个本地大模型运行器。它不是模型本身,而是负责模型下载、模型管理、本地推理和 API 服务。
无论您是在为YOLO、SAM还是自定义模型准备数据集,VisioFirm都能通过其直观的Web界面和强大的后端,显著优化您的工作流程。在AI模型训练的数据 pipeline 中,高质量的标注数据已成为新的“瓶颈”。其技术核心通常包含一个强大的基础模型,例如基于SAM(Segment Anything Model) 的零样本分割引擎,能够根据用户的简单点击,瞬间勾勒出任何目标的精准像素级掩码。这种“

BPE 是一种子词切分方法,本质上通过合并高频相邻符号构建词表。训练阶段按频率做 merge,得到固定规则和优先级。推理阶段不会重新学习,也不会重新统计频率,只会执行已保存的 merge 规则。训练阶段的 8k、32k、50k 等限制,控制的是 tokenizer 规模;推理阶段没有面向单条输入的额外 merge 次数上限,而是一直合并到不能再合并为止。merge 规则通常保存在 tokenize

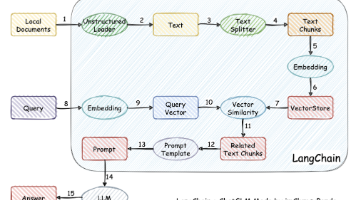
文档被解析出来之后,通常不会整篇作为一个整体去检索,而是会被切成多个小块,也就是常说的 chunk。很多初学者会以为 chunk 只是“按长度切分文本”,但真正好的 chunk 远不止如此。它本质上是在定义:知识库里,什么才算一个适合被召回的最小语义单元。如果一个 chunk 太小,语义往往不完整,用户问题明明对应某一段内容,却只能召回零散句子;如果一个 chunk 太大,虽然信息完整,但相似度检
无论您是在为YOLO、SAM还是自定义模型准备数据集,VisioFirm都能通过其直观的Web界面和强大的后端,显著优化您的工作流程。在AI模型训练的数据 pipeline 中,高质量的标注数据已成为新的“瓶颈”。其技术核心通常包含一个强大的基础模型,例如基于SAM(Segment Anything Model) 的零样本分割引擎,能够根据用户的简单点击,瞬间勾勒出任何目标的精准像素级掩码。这种“
HIT-UAV。

无论您是在为YOLO、SAM还是自定义模型准备数据集,VisioFirm都能通过其直观的Web界面和强大的后端,显著优化您的工作流程。在AI模型训练的数据 pipeline 中,高质量的标注数据已成为新的“瓶颈”。其技术核心通常包含一个强大的基础模型,例如基于SAM(Segment Anything Model) 的零样本分割引擎,能够根据用户的简单点击,瞬间勾勒出任何目标的精准像素级掩码。这种“