




- @qq_45972323
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
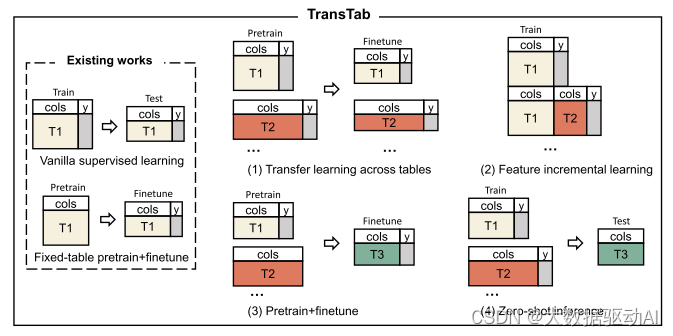
表格数据(或表格)是机器学习(ML)中使用最广泛的数据格式。然而,ML模型通常假设表结构在训练和测试中保持固定。在ML建模之前,需要进行大量的数据清理,以合并具有不同列的不同表。这种预处理通常会导致显著的数据浪费(例如,移除不匹配的柱和样品)。如何从具有部分重叠列的多个表中学习ML模型?如何随着时间的推移随着更多列变得可用而增量地更新ML模型?我们可以在多个不同的表上利用模型预训练吗?如何训练一个
#json数据格式问题,可能是请求过于频繁,网站没有返回正常的数据#每天早上起床时可以运行,到下午后就一直报错。import requestsimport jsonimport csvfor page_num in range(49):new_url = f'https://club.jd.com/comment/productPageComments.action?productId=10023
在cmd中输入pip check如果我们一些关于python的库版本不对,或不存在该库,pip check 会将所需直接显现出来
我的是物理服务器:这是将服务器硬件直接放置在您自己的数据中心或机房的传统方法。这种方法需要更多的设备和维护工作,但提供更高的灵活性和控制权。使用Docker,可以将Python程序及其依赖项打包成一个镜像,并在服务器上运行该镜像。优点:Docker部署Python程序,可以提供更好的可移植性和可扩展性、可以在不同的服务器和环境中轻松地运行相同的镜像。优点:服务器less技术部署Python程序,可

•/etc/profile —— 此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行.并从/etc/profile.d目录的配置文件中搜集shell的设置;联想到修改/etc/environment文件时确实对PATH进行过操作,所以解决问题的最简单的方法就是让/etc/environment恢复到修改之前的状态。因此要编辑/etc/environment要使用的命令应该这样写:

大数据开发基础实验二

•/etc/profile —— 此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行.并从/etc/profile.d目录的配置文件中搜集shell的设置;联想到修改/etc/environment文件时确实对PATH进行过操作,所以解决问题的最简单的方法就是让/etc/environment恢复到修改之前的状态。因此要编辑/etc/environment要使用的命令应该这样写:
