- @qq_45889056
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Anthropic在Claude Code最新版本中秘密加入了Workflow功能,这是一个革命性的多Agent协作编排系统。用户通过编写JavaScript脚本可以精确定义任务阶段、Agent角色和执行流程,实现可观测、可结构化、可复用的任务编排。Workflow支持六种执行形态,包括流水线、并行聚合等,并能保存为脚本供后续复用。与临时派生子Agent或并行会话等传统方式不同,Workflow首
Anthropic在Claude Code最新版本中秘密加入了Workflow功能,这是一个革命性的多Agent协作编排系统。用户通过编写JavaScript脚本可以精确定义任务阶段、Agent角色和执行流程,实现可观测、可结构化、可复用的任务编排。Workflow支持六种执行形态,包括流水线、并行聚合等,并能保存为脚本供后续复用。与临时派生子Agent或并行会话等传统方式不同,Workflow首
我们在让Agent实现自我进化方面,正取得前所未有的突破。从早期自动Agent Persia(受 Andrew Ng 自动研究概念启发),到利用 Claude Code 实现自我进化的代码Agent,再到在电子表格和终端分支任务中双双拿下第一的壮举——生态正在以惊人的速度迭代。更有开发者从 Anthropic 泄露的源代码中挖出了隐藏的功能,能将计算代码转化为学习经验与最佳实践。正是在这种背景下,
策略学习的意思是通过求解一个优化问题,学出最优策略函数πa∣s或它的近似函数(比如策略网络)。
本文介绍了通过Docker运行容器并使用VSCode远程连接的操作指南。主要内容包括:1) 拉取并运行Docker镜像,设置端口映射(8080:22);2) 使用VSCode的Remote-SSH插件配置连接;3) 常见问题排查方法,如SSH服务未启动、root登录限制等;4) 服务器端口放行设置。文章提供了完整的操作流程和详细的参数说明,帮助用户实现从本地VSCode到Docker容器的SSH远
关于 Episode length的设置,理论上应该是无穷大的(agent到达目标点后选择action为不动),但实际中需要一个确切的值,值越大越接近最优的策略,此时对应的state value也是最终的值。注意,这里s2,s3情况下的策略是最优的,所有改进策略一定是有效的,但可以证明,无论后面的策略是否最优,都可以经过action value的迭代最终达到最优策略。,此时我们不知道g(w)的具体
比如,在一个迷宫寻路问题中,除了给出到达终点的正奖励和每走一步的负奖励外,还可以给出接近终点的正奖励或远离终点的负奖励,以引导智能体更快地找到正确的路径。正奖励表示智能体做出的行为对任务有益,负奖励表示行为有害,而零奖励表示行为没有影响。过小的奖励可能无法提供足够的鼓励,从而导致智能体无法学会任务,过大的奖励可能会导致智能体出现过度拟合的现象,或者出现在任务中没有意义的行为。稀疏的奖励可能会导致智
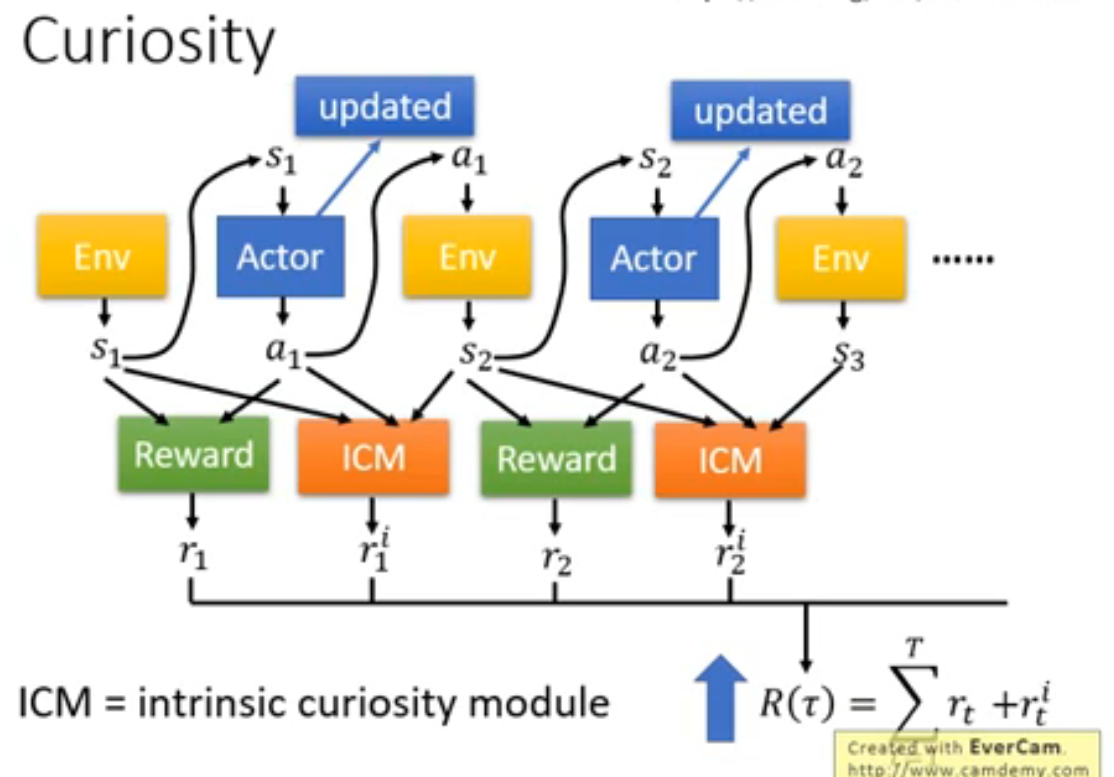
在强化学习任务中,特别是在策略梯度方法中,通常不需要一个完整的Transformer模型,包括Encoder和Decoder。因此,我们可以只使用Transformer的Encoder部分,将状态作为输入,经过编码后得到一个表示状态的向量,然后将这个向量传递给策略网络(或者Critic网络)来进行动作选择或值函数估计。使用Transformer的Encoder部分可以有效地处理状态的变长输入,并且

策略学习的意思是通过求解一个优化问题,学出最优策略函数πa∣s或它的近似函数(比如策略网络)。
Q⋆Qsa;wQ∗sa。