




- @qq_45668004
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
核心贡献公开了 GR00T-N1-2B 模型权重、训练数据、仿真环境(GitHub+HuggingFace),降低通用机器人研究门槛;技术突破:双系统 VLA 架构解决 “推理慢 + 动作笨” 的矛盾,数据金字塔解决 “数据稀缺”,为后续通用机器人模型提供范式;落地验证:在真实 GR-1 人形机器人上实现 “语言指令控制双手操作”,证明基础模型在人形机器人上的可行性。局限性任务范围:目前仅支持 “

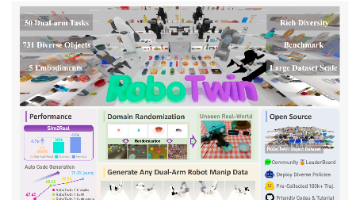
本文提出了,一个可扩展的仿真框架,通过集成 MLLM-based 任务生成、本体适应行为合成和全面的领域随机化,解决了现有合成数据生成方法的局限性。实验结果表明,RoboTwin 2.0 在提高策略对杂乱环境的鲁棒性、对未见任务的泛化能力以及跨本体操作方面具有显著效果。该框架为鲁棒的双臂操作提供了统一的基准和可扩展的仿真到现实管道,未来的工作将重点放在现实世界部署和多对象任务复杂性上。
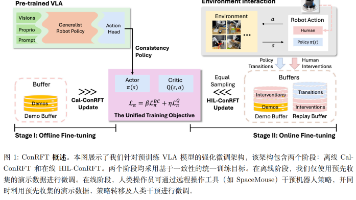
ConRFT 是一种高效、安全、实用的VLA模型强化微调方法,只需 20 个演示+ 1 小时在线训练,就能让机器人在复杂真实任务中达到 96% 成功率,比传统方法快、稳、强。后续可探索 “更智能的奖励设计”“感知 - 动作联合微调”,进一步提升 VLA 模型的通用操控能力。
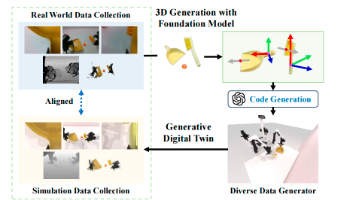
RoboBench是一个面向具身智能的多模态大语言模型评估基准,旨在系统性评估 MLLMs 作为机器人"具身大脑"的认知能力。该基准针对动态非结构化环境中的操作任务,定义了五个核心评估维度:指令理解、感知推理、广义规划、可操作性预测和失败分析,覆盖 14 项能力、25 项任务和 6092 个问答对。1)构建真实场景数据集,整合大规模真实机器人数据与自采数据,涵盖单臂/双臂/移动操作、多视角遮挡场景

关键词:#具身智能 #双臂机器人 #benchmark。
pi0 是 VLA 发展史上一个重要的里程碑式模型,提出了一个基于 VLM 的 flow matching 架构,通过机器人动作模态的扩展训练,将其升级为 VLA 模型,实现了一个通用机器人的控制策略。
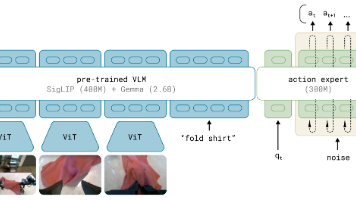
pi0 是 VLA 发展史上一个重要的里程碑式模型,提出了一个基于 VLM 的 flow matching 架构,通过机器人动作模态的扩展训练,将其升级为 VLA 模型,实现了一个通用机器人的控制策略。
ConRFT 是一种高效、安全、实用的VLA模型强化微调方法,只需 20 个演示+ 1 小时在线训练,就能让机器人在复杂真实任务中达到 96% 成功率,比传统方法快、稳、强。后续可探索 “更智能的奖励设计”“感知 - 动作联合微调”,进一步提升 VLA 模型的通用操控能力。
RoboBench是一个面向具身智能的多模态大语言模型评估基准,旨在系统性评估 MLLMs 作为机器人"具身大脑"的认知能力。该基准针对动态非结构化环境中的操作任务,定义了五个核心评估维度:指令理解、感知推理、广义规划、可操作性预测和失败分析,覆盖 14 项能力、25 项任务和 6092 个问答对。1)构建真实场景数据集,整合大规模真实机器人数据与自采数据,涵盖单臂/双臂/移动操作、多视角遮挡场景
轻量化:0.77B 参数,大幅降低训练 / 部署成本;免预训练:无需大规模机器人数据,数据收集成本骤降;强泛化:两阶段训练保护语义表征,面对干扰(如背景变化、目标移位)仍稳定;高实用:实时推理 + 低显存,适配消费级 GPU 和真实机器人场景。为推动未来研究,作者团队公开了代码、训练数据和模型权重,以鼓励轻量级高性能 VLA 模型的进一步研究与实际开发。
