




- @qq_42990803
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一、HDFS概念HDFS (Hadoop Distributed File System)指适合运行在通用硬件上的分布式文件系统二、HDFS特点和特性现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。1. 高容错性适合部署在廉价的机器上2. 高吞吐量为大量数据访问的应用提供高吞吐量支持3. 大文件存储支持存储TB-PB级别的数据HDFS适用于大文件存储、流式数据
AI就像一个黑匣子,能自己做出决定,但是人们并不清楚其中缘由。因此,需要了解AI如何得出某个结论背后的原因,而不是仅仅接受一个在没有上下文或解释的情况下输出的结果。
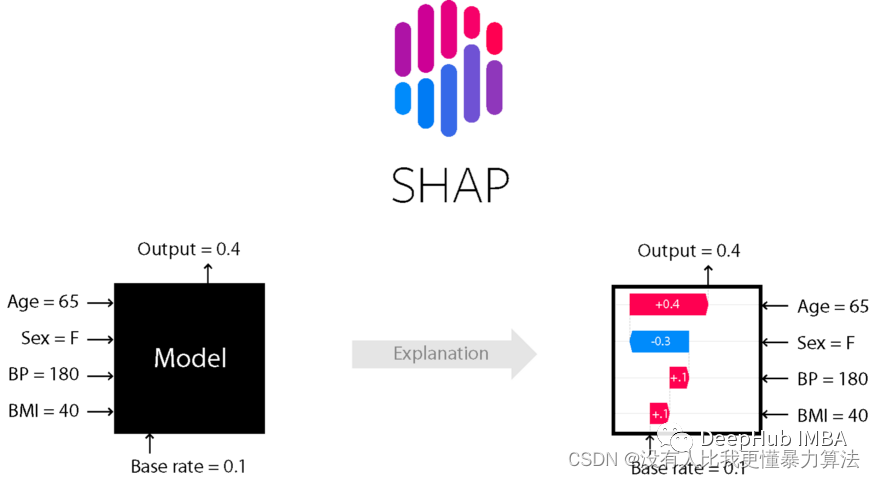
本文整体介绍了当前模型可解释性领域有哪些主流的研究方法?应用前景如何?应用落地存在哪些挑战?
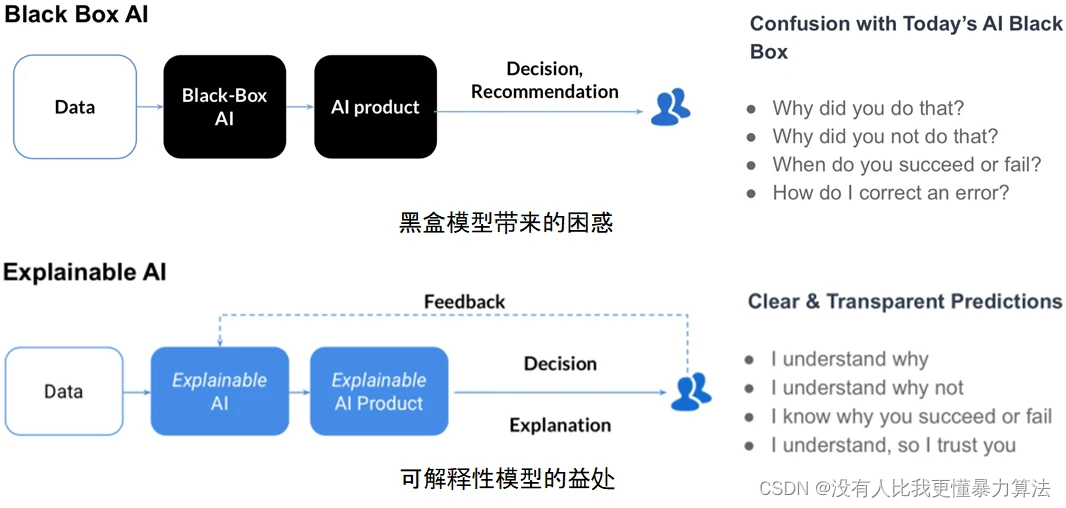
本文整体介绍了当前模型可解释性领域有哪些主流的研究方法?应用前景如何?应用落地存在哪些挑战?
本文整体介绍了当前模型可解释性领域有哪些主流的研究方法?应用前景如何?应用落地存在哪些挑战?
通过 Java Util 类的 Arrays.fill(arrayname,value) 方法和Arrays.fill(arrayname ,starting index ,ending index ,value) 方法向数组中填充元素public class FillTest {public static void main(String args[]) {int array[] = new i
介绍两类可解释性机器学习模型SHAP 和LIME,其工作原理和举例说明。
Home FrontEnd Wiki PaperReading Github Others About浙江大学-数据挖掘课程-复习笔记介绍什么是数据挖掘:抽取interesting pattern数据挖掘的过程:knowledge discovery 过程KDD可以被挖掘的patterngeneralization(概括)Information integration 信息聚合,数据仓库的构建(数
1、论文希望解决的问题:Transactional data changes over time,Many algorithms for mining high-utility itemsets (HUI) ignore this important property and thus are inapplicable or generate inaccurate results on real