




- @qq_42734492
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
VGG变种
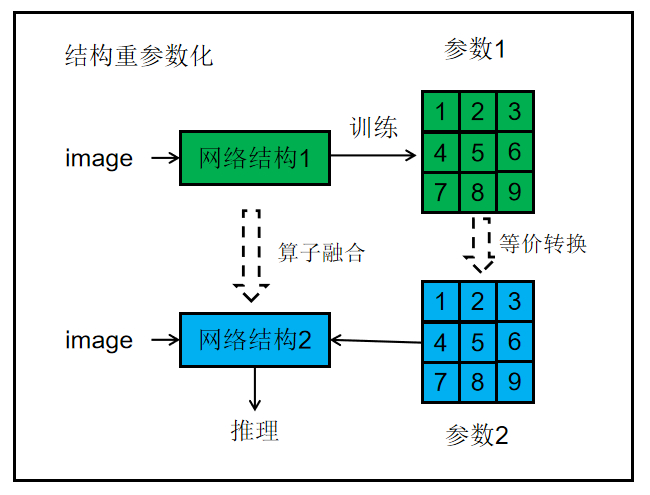
本文来自公众号“AI大道理”yolo v3的预测结果就是我们想要的最终的预测框。从原始图片到框出物体的图片,这中间经历了什么呢?预测过程(1)添加灰条yolo v3需要输入416*416大小的图片,然而我们采集的图片未必都是这样的尺寸。若直接resize,图片会被拉伸导致失真的。给图像增加灰条,实现不失真的resize。(2)获得预测参数这样输入后就可以获得网格的预测结果,将结果保存到list里
本文来自公众号“AI大道理SPP对于一个CNN模型,可以将其分为两个部分:前面包含卷积层、激活函数层、池化层的特征提取网络,下称CNN_Pre,后面的全连接网络,下称CNN_Post。许多CNN模型都对输入的图片大小有要求,实际上CNN_Pre对输入的图片没有要求,可以简单认为其将图片缩小了固定的倍数,而CNN_Post对输入的维度有要求。SPP:空间金字塔池化,无论CNN_Pre输出的feat
本文来自公众号“AI大道理”YOLO v2 是 YOLO v1的进阶版,它没有彻底否定 YOLO v1,而是在 YOLO v1 的基础上,融合了很多其它论文优秀的思想做了大幅的提升。YOLO v1 比较低的召回率和比较高的定位误差。所以,让 YOLO v1变得更好指的是保持准确率的情况下:提升召回率降低定位误差YOLO v2的思想1)Batch NormalizationBatch Norm...
本文来自公众号“AI大道理”转自 | 青云原文 |https://blog.csdn.net/m0_45962052/article/details/105199178YOLO v3 是目前工业界用的非常多的目标检测的算法。YOLO v3 没有太多的创新,主要是借鉴一些好的方案融合到 YOLO v2 里面。不过效果还是不错的,在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力
本文来自公众号“AI大道理”为什么会有ResNet?神经网络叠的越深,则学习出的效果就一定会越好吗?答案无疑是否定的,人们发现当模型层数增加到某种程度,模型的效果将会不升反降。也就是说,深度模型发生了退化情况。那么,为什么会出现这种情况?按理说,当我们堆叠一个模型时,理所当然的会认为效果会越堆越好。因为,假设一个比较浅的网络已经可以达到不错的效果,那么即使之后堆上去的网络什么也不做,模型的效果也不
本文来自公众号“每日一醒”Yolo v5一共有四个模型,分别为Yolov5s、Yolov5m、Yolov5l、Yolov5x。Yolov5s网络最小,速度最少,AP精度也最低,如果检测的以大目标为主,追求速度,倒也是个不错的选择。其他的三种网络,在此基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。YOLOV5的改进1、backbone:CSPDarkNet53+Focus
论文原文:https://arxiv.org/abs/2204.068061、摘要这篇文章介绍了YoLoPose,基于流行的YOLO框架,实现了一种新颖的无热力图的关节检测与2D多人姿态估计。当前,基于热力图的方法是两个阶段,这个方法并不是最优的,因为他们不是端到端训练的,并且训练依赖于可替代的L1损失,它并不等同于最大化评估策略,即目标关键点相似度(object keypoint similar

上一专题搭建了一套GMM-HMM系统,来识别连续0123456789的英文语音。但若不是仅针对数字,而是所有普通词汇,可能达到十几万个词,解码过程将非常复杂,识别结果组合太多,识别结果不会理想。因此只有声学模型是完全不够的,需要引入语言模型来约束识别结果。让“今天天气很好”的概率高于“今天天汽很好”的概率,得到声学模型概率高,又符合表达的句子。1 语言模型真面目定义:对于语言序列词ω1,ω2,ω3
本文来自公众号“AI大道理目标检测或者实例分割不仅要关心语义信息,还要关注图像的精确到像素点的浅层信息。所以需要对骨干网络中的网络层进行融合,使其同时具有深层的语义信息和浅层的纹理信息。PANet整体结构PANet(Path Aggregation Network)最大的贡献是提出了一个自顶向下和自底向上的双向融合骨干网络,同时在最底层和最高层之间添加了一条“short-cut”,用于缩短层之间