




- @qq_41990268
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了如何在LM Studio中启用MTP功能来提升大语言模型的运行效率。作者以7840hs的780M核显为例,展示了更新软件版本、配置开发者模式、选择支持MTP的模型等关键步骤。实测结果显示,启用MTP后,思考时间从1分49秒缩短至1分32秒(提升15.6%),回答生成速度从3.5t/s提升到6.71t/s(提升91.7%)。文章还通过"虎鲸是否是鱼"的问答示例,展示了模型在启用MTP后的性
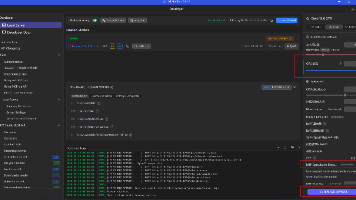
本文探讨了LM Studio中GPU卸载参数对Token生成速度的影响。通过对比默认GPU卸载=4和提升至64的情况,发现提高GPU卸载能显著提升性能:思考时间从3分58秒缩短至1分49秒(提升54.2%),Token生成速度从2.64t/s提升到3.5t/s(提升32.58%)。测试使用7840hs处理器和780M核显,96GB内存中分配48GB给核显运行Q4 30b模型。结果表明合理配置GPU
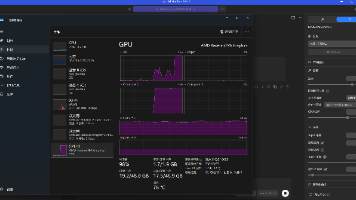
本文介绍了如何在LM Studio中启用MTP功能来提升大语言模型的运行效率。作者以7840hs的780M核显为例,展示了更新软件版本、配置开发者模式、选择支持MTP的模型等关键步骤。实测结果显示,启用MTP后,思考时间从1分49秒缩短至1分32秒(提升15.6%),回答生成速度从3.5t/s提升到6.71t/s(提升91.7%)。文章还通过"虎鲸是否是鱼"的问答示例,展示了模型在启用MTP后的性
本文介绍了如何在LM Studio中启用MTP功能来提升大语言模型的运行效率。作者以7840hs的780M核显为例,展示了更新软件版本、配置开发者模式、选择支持MTP的模型等关键步骤。实测结果显示,启用MTP后,思考时间从1分49秒缩短至1分32秒(提升15.6%),回答生成速度从3.5t/s提升到6.71t/s(提升91.7%)。文章还通过"虎鲸是否是鱼"的问答示例,展示了模型在启用MTP后的性
本文探讨了LM Studio中GPU卸载参数对Token生成速度的影响。通过对比默认GPU卸载=4和提升至64的情况,发现提高GPU卸载能显著提升性能:思考时间从3分58秒缩短至1分49秒(提升54.2%),Token生成速度从2.64t/s提升到3.5t/s(提升32.58%)。测试使用7840hs处理器和780M核显,96GB内存中分配48GB给核显运行Q4 30b模型。结果表明合理配置GPU
虎彩首个不含PLC的运动控制系统。技术栈:脉冲控制,步进控制,C#基础。
解决HBase的ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing报错
本文将以大数据开发中最常见的数仓组件Hive的drop table为例,抛砖引玉,解读为神马大数据开发可以脱离SQL、Java、Scala。

USDP大数据集群及组件的启停
Win10环境借助基于ComfyUI的图狗2.3.1抢先体验阿里万相wan2.1的文生视频功能
