




- @qq_41950533
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
绝大部分参考https://blog.csdn.net/qq_41336087/article/details/129661850。非orin可以参考https://blog.csdn.net/JineD/article/details/131201121。参考https://blog.csdn.net/qq_44235661/article/details/134105151。参考:https:
目前TheJapaneseFemaleFacialExpression(JAFFE)Database、CASIA-WebFace、CAS-PEAL、和个人制作的数据集是可以使用的,其中最符合预期的就是CAS-PEALhttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttps。
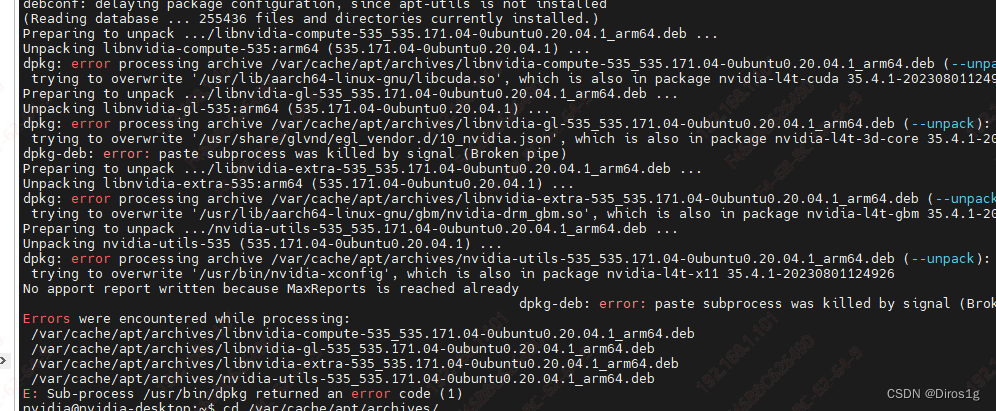
和lsblk显示的都不对。

0.摘要目的是证明sr是否可以对低分辨率的目标检测任务做出贡献,这篇文章加入了用来计算sr过程中的检测损失。本文想要找来一个鲁棒性比较好的sr方法,可以广泛应用于低分辨率的目标检测中,并且证明其有效性。1.病态的srSR的最终目标仍然是按照人类视觉感知的标准尽可能地重建图像,但是人的感知和机器的感知不同。所以如果我们sr的目的是为了给机器使用,我们应该使用更迎合机器的sr方法而不是使用那些迎合肉眼
0.摘要作者:何凯明ILSVRC2014比赛上物体检测上排名第2,在物体分类上排名第3SPP 显著特点支持多尺度输入使用多个窗口(pooling window)SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。在一般的CNN结构中,在卷积层后面通常连接着全连接。而全连接层的特征数是固定的,所以在网络输入的时候,会固定输入的大小,因此会采取一些裁剪(crop)和拉伸(
Single Shot MultiBox Detector论文学习single shot指的是SSD算法属于one-stage方法,MultiBox说明SSD是多框预测。ssd和yolo都是一步式检测器,yolov1的一个缺点就是不擅长做小目标识别,ssd正好克服了这个问题,ssd的一个优势就是准确率高,但ssd512版本fps比yolo低。1.采用多尺度特征图用于检测卷积神经网络一般是个金字塔结
ICCV211.背景One-stage的目标检测是对目标的分类和定位进行同时进行,这种目标检测有两个平行分支的头部,这可能会导致两个任务之间的预测出现一定程度的空间错位。现有的单阶段方法都通过一定的手段来实现两个任务的统一,也就是使用目标的中心点。最近的单级物体探测器试图通过聚焦物体的中心来预测两个独立任务的一致输出。位于物体中心的锚(无锚探测器的锚定点,或基于锚的探测器的anchor-box)可
0.摘要何恺明在提出resnet网络之后,有提出的一个目标检测框架,mask rcnn可以针对各个类别生产相应的掩码,0、1对应检测的背景和检测的目标,所以有着可以语义分割的特性,作者还说它可以进行行为分析。ResNet+FPN+Fast RCNN(RPN)+Mask=Mask rcnn1.回顾Fast RCNNFaster RCNN使用CNN提取图像特征,然后使用RPN去提取出ROI,然后使用R
cvpr2021论文:https://arxiv.org/pdf/2106.08322v1.pdf代码:https://github.com/microsoft/DynamicHead1、摘要作者认为目标检测的头部是由三个部分组成:首先,头部应该是尺度感知的,因为多个具有极大不同尺度的物体经常共存于一幅图像中,FPN。其次,头部应该是空间感知的,因为物体通常在不同的视点下以不同的形状、旋转和位置出
特点:self-attention layers,end-to-end set predictions,bipartite matching lossThe DETR model有两个重要部分:1)保证真实值与预测值之间唯一匹配的集合预测损失。2)一个可以预测(一次性)目标集合和对他们关系建模的架构。3)由于是加了自注意力机制,而且在学习的过程中,观众的注意力训练的很好,每个人的关注点都不一样,所