




- @qq_41946216
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
langchain是一个用于开发由语言模型驱动的应用程序的框架,致力于简化AI模型应用的开发。简单来说,langchain就是一个(帮助开发者轻松完成AI模型应用开发的)框架,现在支持python和js两个版本,它集成多种大语言模型及第三方API。是调节文本多样性的,让回答更加丰富,为0时就会更加准确,大于0回答的就会带有llm的思维回答(可能会胡编乱造)就是回答内容了,回答的一个字典包含了que

简单理解:射频的就是电磁波,频率在3kHz~300GHz范围内的电磁波定义为射频。
假设现在我们要基于中断来实现一个需求,有一个计数器,初始值为0,每次按下按钮开关并释放时,计数值加1,需要定期通过串口打印计数器的当前值。基于Freertos,创建一个任务,该任务不断对一个计数器进行累加,并且该任务绑定到0号CPU,任务优先级为1。保持实验二中的代码不变,仅修改创建任务的逻辑,将任务优先级调整成0,仍然绑定到0号CPU上。保持实验二中的代码不变,仅修改任务逻辑,每次计数器+1后,
要求: LED灯每秒闪烁一次。设备:Esp32开发板、面包板、led灯珠、电阻150欧实现代码:#define LED_PIN 23 // 23号引脚。
本文介绍了ESP32中断机制及应用实例。硬件中断是响应外部突发事件的被动处理(如按键触发),软件中断则是执行预设任务的主动处理(如定时器触发)。ESP32通过attachInterrupt()函数设置中断,需指定引脚、中断处理函数和触发模式(上升沿/下降沿等)。中断处理应简洁高效,耗时任务需交给主循环。文中提供了具体案例:通过23号引脚按钮控制2号引脚的LED灯,利用下降沿中断实现按键翻转LED状
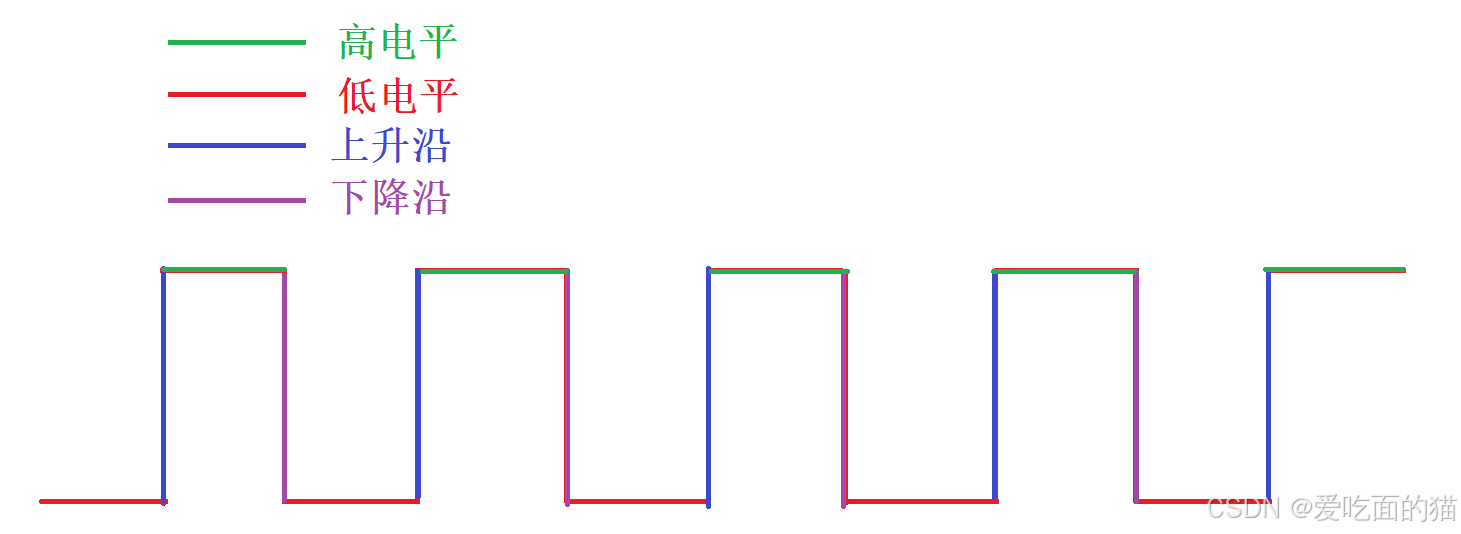
复杂的网络结构:经过LeNet又出现了LSNet、Resnet、Vgg等复杂的网络结构,这些网路结构往往是用来增加网络的深度,因为网络越深,非线性表达能力越强,得到物体更加抽象的表达,对于图像的变化敏感度越不敏感,鲁棒性越强,解决非线性任务能力越强,同时也会导致梯度消失或梯度弥散。输入图片------对图片进行深度特征的提取(主干神经网络)------对目标的位置进行定位和分类,One-stage

YOLO是一种新的目标检测方法。以前的目标检测方法通过重新利用分类器来执行检测。与先前的方案不同,将目标检测看作回归问题从空间上定位边界框(bounding box)并预测该框的类别概率。使用单个神经网络,在一次评估中直接从完整图像上预测边界框和类别概率。由于整个检测流程仅用一个网络,所以可以直接对检测性能进行端到端的优化。

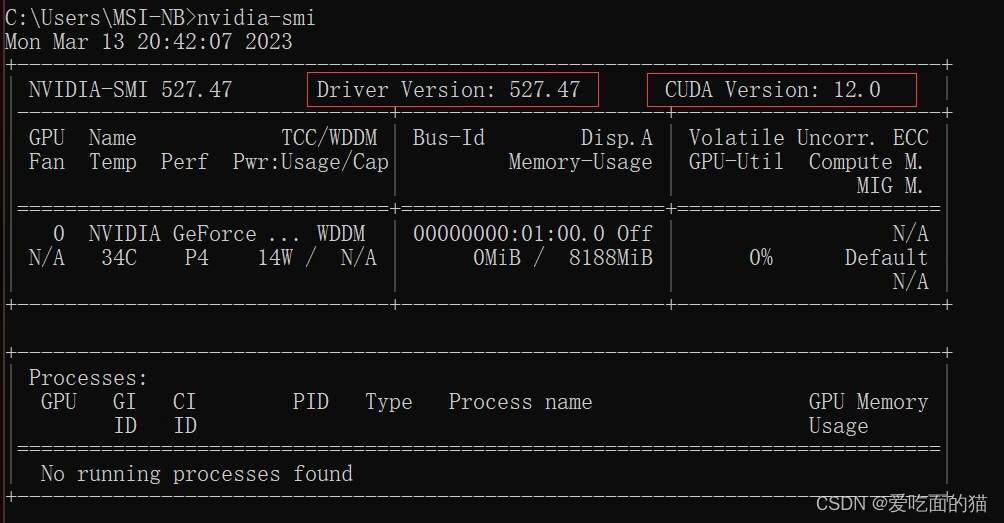
此案例是以win11环境为案例,进行深度学习环境搭建,选择工具及版本分别为CUDA 11.7、Pytouch1.12.1、Miniconda3_py38(含Python3.8)
为方便大家理解YOLO的原理,这里将YOLOv1的部分内容基础内容进行用比较直白的话和例子进行阐述,为后续大家学习YOLO作为铺垫。1、模型所干的活工作中,大家经常将 Word 文档 上传到某转换器,然后转换输出为PDF文档。目标检测中我们想做的事也类似,就是输入一张图,输出一张带有框(标注对应的物体)的图片。如下图所示:问题:这个框是如何还出来的呢?通过模型画出来的,这模型就相当于 word到p
本篇文字是【深度学习】YOLOV5-WIN11环境搭建(配置+训练),首先介绍win11下 基于Anaconda、pytorch的YOLOV5深度学习环境搭建,环境配置顺序:显卡驱动 - CUDA - cudnn - Anaconda - pytorch - pychorm,按这个顺序配置可以避免很多莫名其妙的错误出现。另外不用单独安装python,使用Anaconda里的python环境。做深度