




- @qq_41597915
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
免费白嫖5000万token,还能本地部署满血deepseek的方法我这就教给大家

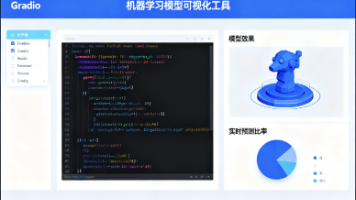
Gradio是一款开源的Python库,可快速为机器学习模型构建交互式Web界面,无需前端知识。本文详细介绍了Gradio的核心功能:1)通过Interface组件快速搭建简单界面;2)使用Blocks组件构建复杂交互逻辑;3)丰富的输入输出组件支持;4)界面共享与部署方案;5)自定义样式技巧。文章结合文本反转、图像分类等实战案例,展示了如何用几行代码实现模型可视化,并提供了常见问题解决方案。Gr
装袋算法是一种提高分类准确度的算法,通过给定组合投票的方式获得最优解。比如你生病了去看医生,每个医生都给你开了药方,最后哪个药方的出现次数多 ,就说明这个药方越有可能是最优解,这就是装袋算法的思想。主要的三种装袋算法模型:装袋决策树 CBagge Decision ees )随机森林(Random Forest )极端随机树 CExtra Trees )装袋决策树:以最常见的装袋决策树为例,skl
这本笔记是关于pytorch的全面学习资料,基本包括了pytorch使用的方方面面。并且在几乎每一个重要的使用场景都给出了代码示例。现把它记录在此,可以作为我的pytorch的使用手册。
这本笔记是关于pytorch的全面学习资料,基本包括了pytorch使用的方方面面。并且在几乎每一个重要的使用场景都给出了代码示例。现把它记录在此,可以作为我的pytorch的使用手册。
Python Django项目完整的上线部署流程,采用Nginx+uwsgi+MySQL的配置方案
免费白嫖5000万token,还能本地部署满血deepseek的方法我这就教给大家
现在很多网站用的是动态网页加载技术,这时候用前面的request库和BS4库就不能解决问题了,需要用新的办法。打开网页,按F12或者右键弹出菜单里选择“检查”,右侧会打开开发者工具。这里有一排菜单,最左边的是Element,显示的是网页的源代码,如果在这里能直接找到所需要爬取的内容,就说明这是静态页面,可以用 request库和BeautifulSoup4库的工具爬取所需内容。如果这里找不到所需内
原文链接:https://www.jianshu.com/p/91844c5bca78声明:本篇文章为转载自https://www.jianshu.com/p/91844c5bca78,在原作者的基础上添加目录导航,旨在帮助大家以更高效率进行学习和开发。Python-Tkinter 图形化界面设计(详细教程)本文目录三、tkinter常见控件的特征属性3.1、文本输入和输出相关控件一、图形化界面设