- @qq_41301570
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
正例图像以P+数字序号命名,反例图像以N+数字序号命名,所有图像为PNG格式,尺寸为1280x659和1372x941。UCAS-AOD采用HBB(horizontal bounding box)的标注方法,图像的groundtruth采用txt格式保存,以图像的同名文档方式存储。遥感图像的分类依据是根据成像的介质不同来进行分类的。UCAS-AOD (Zhu et al.,2015)用于飞机和汽车

由两个独立的数据集组成,分别是MVSA-Single数据集和 MVSA-Multi数据集,前者的每条图文对只有一个标注,后者的每条图文对由三个标注者给出。删除 MVSA-Single 数据集中图片和文字标注情感的正负极性不同(存在positive和negative)的图文对,剩余的图文对中,如果图片或者文本的情感有一者为中性(neutral),则选择另一个积极或者消极的标签作为该图文对的情感标签,
是西北工业大学采集的用于轮船的检测的数据,包含4个大类19个小类共2976个船只实例信息。数据集所有图像均来自六个著名的港口,包括海上航行的船只和靠近海岸的船只,船只图像的尺寸范围从300到1500,大多数图像大于1000x600。注:HSRC数据集总数为1680张,但是只有1061张为有效进行标注的图像。在训练集、验证集和测试集中分别包含436、181和444张图像。设计、matlab appd

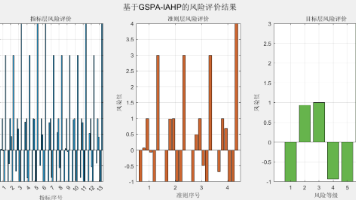
综合运用区间层次分析法和广义集对分析法两种评价方法理论,建立了GSPA-IAHP风险评价模型。从B1、B2、B3、B4四个方面对A进行了风险分析和评价,对A主要的十三个风险C1-C13的评价指标重要度进行了排序,评价结果可知,该评价模型的计算过程简单、实用,体现了该方法的适用性,为类似项目的风险评价提供了参考价值,具有广泛的发展和应用。建立多层次分析结果模型建立区间判断矩阵计算各个指标评价的区间权
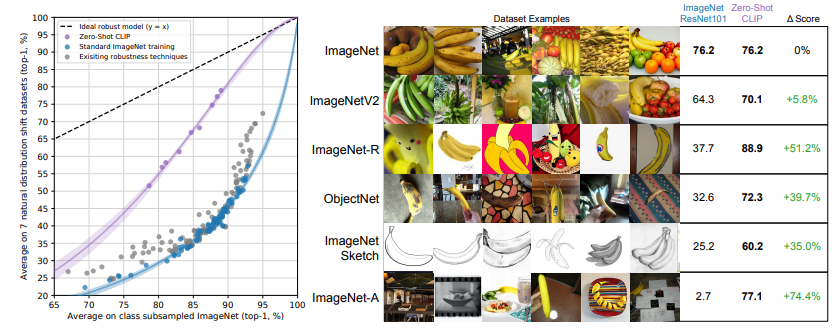
例如,对于ImageNet的类别,可以将其转化为类似"A photo of a {object}"这样的句子,对于ImageNet的1000个类别,就可以生成1000个这样的句子。推理时,将需要分类的图像送入图像编码器以获取特征,然后计算图像特征与1000个文本特征的余弦相似度,选择最相似的文本特征对应的句子,从而完成分类任务。在推理过程中,给定一张图片,通过图像编码器可得到该图片的特征。CLIP
使用的数据集是CPDD2020。训练集5769张,验证集1001张,测试集5006张。类别一类LicensePlate。数据集格式为yolo格式的txt文件。appdesigner,gui设计、simulink仿真......希望能帮到你!图形界面,实现图片、视频及摄像头检测功能,并提供检测结果的实时反馈。:支持上传视频文件,对视频逐帧进行检测,并可视化结果。上传本地图片,进行检测,并展示检测前后

该系列模型包括5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。为此,本项目基于 Qwen-7B大语言模型,通过QLoRA微调,使其从医疗文档中识别并提取这些信息。QLoRA 在不影响模型性能的前提下,将模型参数压缩为 4-bit 格式,并结合 LoRA 微调技术,进一步减少显存占用和计算资源消耗。是一

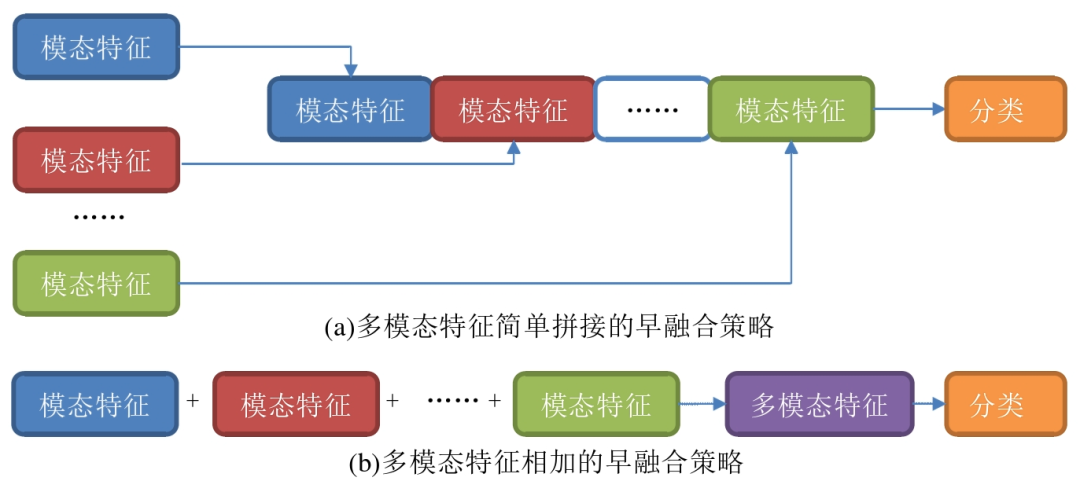
而且在视频中,由于口语的易变性以及伴随的手势和和声音,容易导致的模态内的动态不稳定。首先,采用早融合策略 将各模态特征进行拼接,然后将拼接的特征输入分类器中,并且每个模态的特征也单独输入 分类器中,最终得到所有组合的分类结果,并将所有分类结果进行晚融合策略。提出了一种新的模型Tensor Fusion Network(张量融合网络,TFN),TFN能够端到端地学习模态内和模态间的动态,采用一种新的
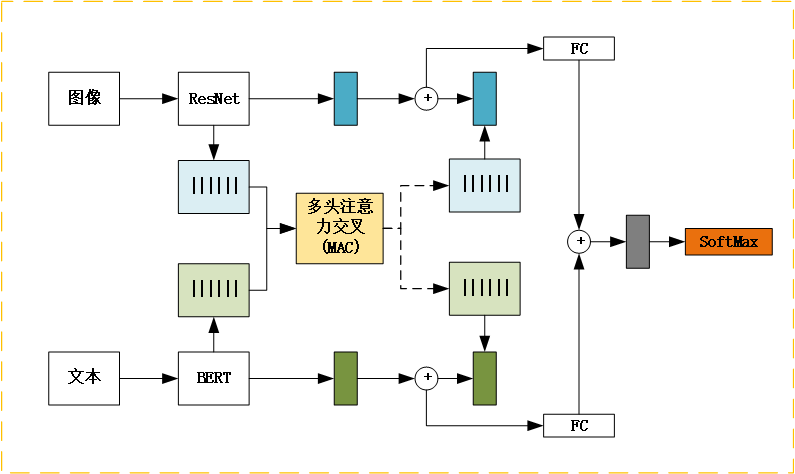
除了多模态处理外,该模型还支持单一模态的处理,即只有文本输入或只有图像输入。接下来,模型将文本和图像的隐藏状态进行拼接,构成共同的特征表示。通过设置attention_mask,模型实现了对文本中padding部分的处理,并使用self-attention机制进行多模态融合。介绍了一种基于BERT和ResNet的多模态模型,该模型在图像和文本信息上进行联合训练,实现了卓越的性能。最后,模型分别提取

在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;人工神经网络(Artificial Neural Network,ANN),简称神经网络(Neural Network)或类神经网络,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型,用于对函数进行估计或近似。由于每一个神经元都会产生一个标量结果,