




- @qq_40999403
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
轨旁设备、车辆部件、巡检图像、工单记录、检修结果,本质上不是孤立数据,而是强关联的业务链条。大数据中心的价值,不是简单汇总数据,而是把巡检图像、视频、传感器数据、设备台账、工单记录、检修结论放入同一框架,形成统一口径、统一命名、统一授权和统一回流机制。大数据中心的价值,在于把分散在线路、工务、车辆、供电等环节的真实数据统一沉淀下来,再通过长尾缺陷补齐机制提升模型边界理解能力。的边界内完成汇聚、治理

没有工作经验背书,创业公司如何筛选人才?顶会论文和可展示的项目成果。资料显示,大厂算法岗现在会直接考察候选人是否在CV、ACL等顶级会议发表过论文。这不是镀金,而是判断“创新底子”的核心依据——一个能在学术界最前沿产出成果的年轻人,比一个只会调参的熟手更有价值。与此同时,项目实战的门槛被AI工具大幅降低。招聘专家指出:“你不需要会写复杂代码,但得有产品思维,能从0到1想清楚一个产品的逻辑。”这意味

CogVLM2作为下一代的视觉语言模型,集成了强大的多模态理解能力,它能够处理复杂的图像和长篇幅的文本,支持用户进行多轮的视觉和文本交互。跨模态理解:理解图像与文本的结合,执行图像描述、问答、视觉推理等任务。长文本处理:处理长达8,000个字符的文本,适合处理长文档和复杂对话。高分辨率图像支持:处理最高1344x1344分辨率的图像,保持视觉细节。多轮对话:支持与用户进行多轮视觉和文本对话,保持对

把视角拉远一些,NemoClaw 推动的是一次观念层面的范式转移:Agent 能否进入生产环境,第一道门槛不是它的聪明程度,而是它的可信程度。NVIDIA 将这套参考堆栈定位为“智慧代理时代的安全操作系统”,背后传递的信号很明确——企业需要的不是又一个 Agent,而是一个能让 Agent 变得可审计、可干预、可预测的治理底座。这个定位对行业规则的影响在于,它可能将“开箱即用的安全护栏”变成未来

作为一名语音技术开发者,我一直在寻找完美的实时语音转录解决方案,直到发现了WhisperLiveKit这个宝藏项目。它不仅解决了传统ASR工具的延迟痛点,还集成了说话人识别功能,真正实现了’所说即所得’的极致体验。今天我要带你深入了解这个基于Python的开源神器,看看它如何通过本地化部署、流式处理技术和智能说话人分离,让语音转录变得前所未有的简单高效。还在为语音转录的延迟抓狂吗?想象一下,会议开

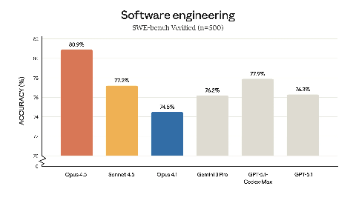
作为一名AI技术观察者和编程爱好者,我不得不告诉你,Anthropic最新发布的Claude Opus 4.5正在重新定义编程的极限。它不仅能在编码、智能代理和计算机应用方面击败人类工程师,还在多项日常任务中表现出色。本文将带你深入探讨Claude Opus 4.5的技术突破、实际应用以及它如何成为编程领域的新标杆。深夜,全球程序员还在为最后一轮代码调试焦头烂额时,已经悄然上线,顺手拿走了“地表最
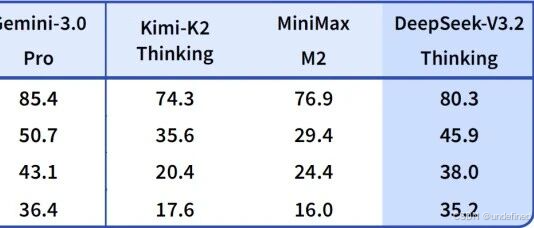
文章概要DeepSeek于2025年12月发布V3.2模型,在可扩展强化学习与智能体AI领域实现关键技术突破。
文章概要在AI辅助编程领域,Obra/superpowers库与Fission-AI/OpenSpec库代表了

银河通用创始人王鹤给出了一个具象化到近乎苛刻的定义:具身智能的“ChatGPT时刻”,意味着机器人在真实场景中,能以70%到80%的成功率完成人类无需专门学习的技能,并具备良好的可部署性。这一定义直接刺破了行业泡沫。互联网上充斥着机器人跑酷、空翻的惊艳视频,但这些Demo往往是在受控环境中反复拍摄的“最优解”。它石智航首席科学家丁文超的批判更为尖锐:判断数据是否有效,关键看模型吸收后的泛化效果能否

银河通用创始人王鹤给出了一个具象化到近乎苛刻的定义:具身智能的“ChatGPT时刻”,意味着机器人在真实场景中,能以70%到80%的成功率完成人类无需专门学习的技能,并具备良好的可部署性。这一定义直接刺破了行业泡沫。互联网上充斥着机器人跑酷、空翻的惊艳视频,但这些Demo往往是在受控环境中反复拍摄的“最优解”。它石智航首席科学家丁文超的批判更为尖锐:判断数据是否有效,关键看模型吸收后的泛化效果能否