




- @qq_40285589
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
视频生成的提示词构成(尽量使用英文),你使用哪个底座模型就去他们的社区或者官网上找到你想要做的风格的视频(sora能看到用户的提示词,wan可以去github看他们大量的示例视频也附上了提示词),去拿到他们公开的提示词,多拿几个丢给gpt让它总结提示词构成模板然后让gpt生成优化几个版本最后再丢到工作流或者api里去抽奖,以便抽奖一边微调。1.设计风格(最好是有一些知名度高的风格如迪士尼,猎魔人,
ViduQ2 白嫖1000积分
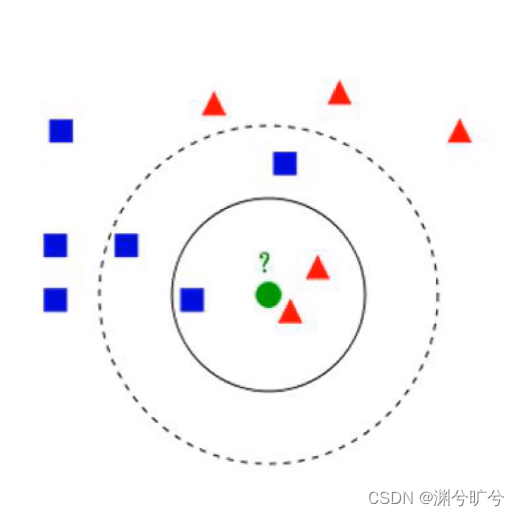
对于机器学习,我们基本遵循三步走套路:1.收集数据并给定标签2.训练一个分类器3.测试,评估其中训练分类器,测试评估便需要用到一定的框架来实现。这里推一下学习或练手用的训练集:(度娘可以直接下,大概600M+)数据库 CIFAR-10该数据库一共有10类标签,每张图片是32*32*3大小,其中共有50000个训练数据,10000个测试数据,对于没有高算力的常规配置电脑是一个比较适合的小型库。
下载后是一个rar文件,解压到各自存储工具的地址,然后打开到bin文件夹(里面正常应该有3个.exe文件),复制文件夹路径。找到红色框选的绿色文字链接,点击下载即可,下载大概率需要魔法,暂时麻瓜的可以先用我上传度盘的(2024/10/10)1.确保已经正确安装ffmpeg,pydub实际上仍然是ffmpeg的功能封装库,底层是依靠ffmpeg来实现的。抱脸上的模型几乎统一输入需求都是.wav,直接

llam2模型部署成本试核算

图像去噪,主要用于去除图像的一些噪点,从而减少乃至消除噪点对边缘检测的影响。图像降噪常见的有均值滤波,高斯滤波,中值滤波,双边滤波,引导滤波等。
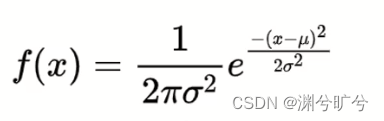
llam2模型部署成本试核算
torch.randn_like():输入与传入参数size相同的满足标准正态分布的随机数字tensor。layout(可选)- 输出张量所需的内存布局。默认为None,这意味着将使用输入张量的内存布局。dtype(可选)- 输出张量所需的数据类型。device(可选)- 输出张量所需的设备。input_tensor(必需)- tensor对象,输出张量的大小与输入对象一致。torch.randn

llam2模型部署成本试核算
llam2模型部署成本试核算