- @qq_39239864
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
MySQL性能优化是一个综合性的过程,涉及多个方面,以下是对MySQL性能优化的详细解析:对于高并发应用,应适当增加 max_connections 的值,以支持更多的并发连接。同时,thread_cache_size 的调整可以减少线程的创建和销毁开销,从而提升性能。如下sql可查询数据库的最大连接数。wait_timeout:设置连接超时时间,当一个连接在指定时间内没有活动时,将被自动关闭。及

Kafka 之所以能实现惊人的高吞吐量(单机可达每秒处理百万级消息),并不是依赖某种“黑魔法”,而是因为它把计算机科学中已有的高效技术组合并发挥到了极致。简单来说,Kafka 的设计核心是:利用操作系统的特性,把磁盘写成内存的速度,把网卡跑满。Kafka 快的原因可以概括为:顺序 I/O 替代随机 I/O,零拷贝替代传统搬运,批量压缩减少传输量,并行分区利用集群算力。
数据库优化是一个系统工程,通常遵循“先软件后硬件,先优化后扩容”的原则。
作为架构师设计高并发微服务架构,落地前必须量化业务指标,作为架构设计的依据,核心思路是围绕流量管控、服务解耦、弹性伸缩、数据分层、高可用保障五大维度展开,从架构分层、组件选型、设计原则到落地实践全链路规划,同时兼顾性能、稳定性、可扩展性与运维成本。
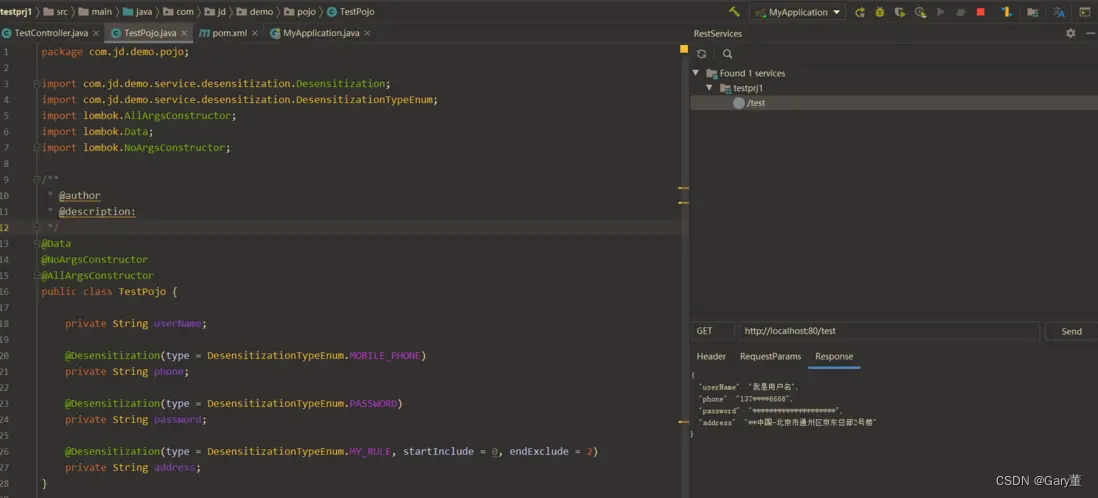
在开发中,我们经常会处理一些敏感数据,比如:身份证号、手机号、银行卡、邮箱等等。为了保护用户的数据安全,我们需要对这些数据进行脱敏处理。JAVA提供了一些工具,可以让我们更加便捷的去处理。@Retention(RetentionPolicy.RUNTIME):运行时生效。@Target(ElementType.FIELD):可用在字段上。@JacksonAnnotationsInside:此注解可
伴随信息量的爆炸式增长以及构建的应用系统越来越多样化、复杂化,特别是企业级应用互联网化的趋势,缓存(Cache)对应用程序性能的优化变的越来越重要。将所需服务请求的数据放在缓存中,既可以提高应用程序的访问效率,又可以减少数据库服务器的压力,从而让用户获得更好的用户体验。定义了 org.springframework.cache.Cache 和 org.springframework.cache.C

在开发中,我们经常会处理一些敏感数据,比如:身份证号、手机号、银行卡、邮箱等等。为了保护用户的数据安全,我们需要对这些数据进行脱敏处理。JAVA提供了一些工具,可以让我们更加便捷的去处理。@Retention(RetentionPolicy.RUNTIME):运行时生效。@Target(ElementType.FIELD):可用在字段上。@JacksonAnnotationsInside:此注解可
2PC/3PC:依赖于数据库,能够很好的提供强一致性和强事务性,但延迟比较高,比较适合传统的单体应用,在同一个方法中存在跨库操作的情况,不适合高并发和高性能要求的场景。TCC:适用于执行时间确定且较短,实时性要求高,对数据一致性要求高,比如互联网金融企业最核心的三个服务:交易、支付、账务。本地消息表/MQ 事务:适用于事务中参与方支持操作幂等,对一致性要求不高,业务上能容忍数据不一致到一个人工检查