




- @qq_38628046
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
执行docker命令时异常: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running

OpenClaw 是本地 AI 助手框架,运行在你的电脑上。支持自动化任务、多平台集成(Telegram、Discord 等)、浏览器自动化和系统监控。通过自定义个性配置,让 AI 理解你的工作方式,构建专属生产力工具。让 AI 真正为你工作。

OpenClaw 是本地 AI 助手框架,运行在你的电脑上。支持自动化任务、多平台集成(Telegram、Discord 等)、浏览器自动化和系统监控。通过自定义个性配置,让 AI 理解你的工作方式,构建专属生产力工具。让 AI 真正为你工作。
Scrapyd是一个用于部署Scrapy爬虫的开源工具。它可以轻松地在多台服务器上部署和运行Scrapy爬虫,并提供了一些有用的功能,例如爬虫版本管理、调度爬虫任务、监控爬虫运行状态等。

Django REST Framework (DRF)提供了一系列的认证与权限功能来保护Web API不被未授权用户访问或滥用。

AOP日志切面拦截出现异常:java.lang.IllegalStateException: It is illegal to call this method if the current request is not in asynchronous mode (i.e. isAsyncStarted() returns false)

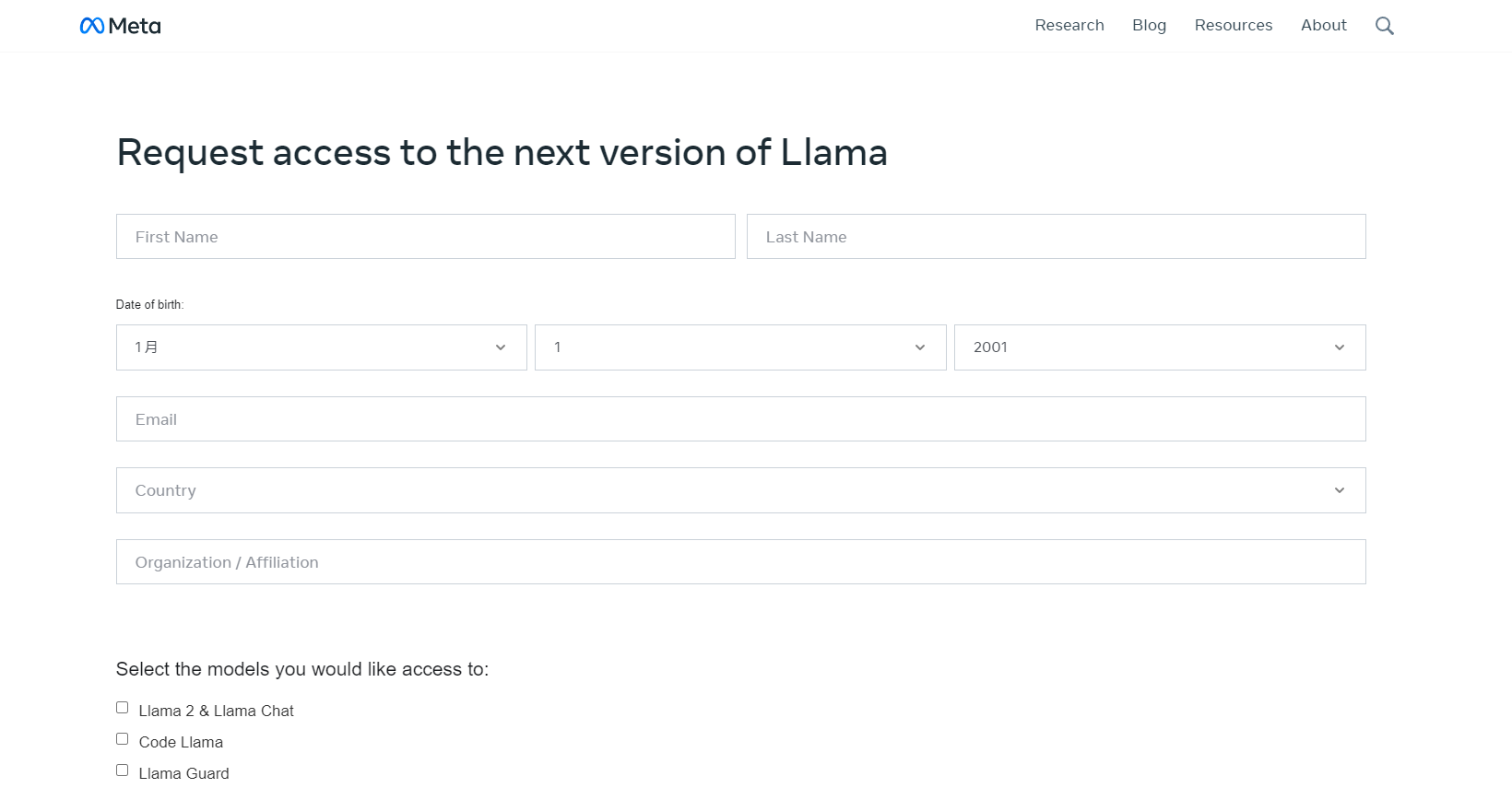
Llama2开源且免费用于研究和商业用途,接受2万亿个标记的训练,上下文长度是Llama1的两倍。Llama2包含了70亿、130亿和700亿参数的模型。
鸿蒙开发环境搭建下载和安装DevEco Studio安装HarmonyOS SDK创建和运行Hello World解决Gradle下载失败更改Gradle默认安装位置下载和安装DevEco StudioHUAWEI DevEco Studio(以下简称DevEco Studio)是基于IntelliJ IDEA Community开源版本打造,面向华为终端全场景多设备的一站式集成开发环境(IDE)
鸿蒙开发之Page Ability的生命周期Page生命周期回调AbilitySlice生命周期Page与AbilitySlice生命周期关联生命周期测试系统管理或用户操作等行为均会引起Page实例在其生命周期的不同状态之间进行转换。Ability类提供的回调机制能够让Page及时感知外界变化,从而正确地应对状态变化(比如释放资源),这有助于提升应用的性能和稳健性。Page生命周期回调Page生命
鸿蒙开发之资源文件资源文件的分类resources目录资源组目录资源文件的使用Java文件引用资源文件的格式普通资源:ResourceTable.type_name系统资源:ohos.global.systemres.ResourceTable.type_name获取profile中的文件内容XML文件引用资源文件的格式普通资源:$type:name系统资源:$ohos:type:name。raw