




- @qq1137623160
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
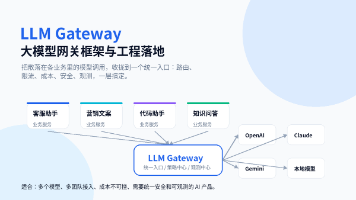
刚开始做 AI 应用时,很多团队都是业务服务直接调用模型 API:客服服务调一个模型,营销服务调一个模型,代码助手再接一个模型。这样做在 Demo 阶段很快,但到了生产环境,问题会集中爆发。不同模型 SDK 和参数格式不一致,API Key 分散在各个服务中,重试和限流逻辑重复实现,成本也无法统一统计。真正上生产后,问题不是“能不能调通模型”,而是“能不能稳定、便宜、安全、可观测地调用模型”。
位置编码解决的是 Transformer 的顺序感问题。sin/cos 给每个位置一张固定身份证,简单但长上下文外推有限;相对位置编码把距离关系直接放进计算,思路更接近语言理解;RoPE 通过旋转 Q/K,把相对距离自然写进点积,兼顾表达力、外推和工程兼容性;ALiBi 用距离惩罚实现简单外推,但表达力相对弱。今天做大模型,尤其是 Decoder-only 模型,RoPE 已经是最常见选择。但无论

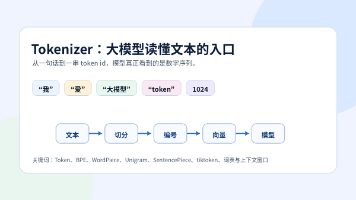
Tokenizer 可以理解成大模型的“文字编码器”。它不负责理解世界,也不负责生成答案,但它决定了文本进入模型之前的形态。切得好,模型更容易学习和泛化;切得差,序列会更长、成本会更高、上下文更容易被挤爆。真正落地时,记住三句话:模型看的是 token id;tokenizer 必须和模型配套;成本、速度、上下文窗口都和 token 数有关。
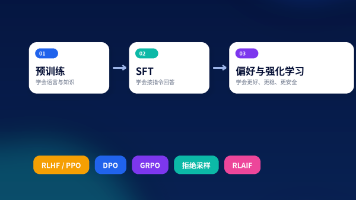
很多人第一次理解大模型训练时,会把它想成“把数据塞进去,模型就会回答问题”。这个说法太粗了。真正的大模型训练更像培养一个新人:先让他读大量资料形成基础能力,再给他看标准问答学会工作方式,最后通过偏好反馈让他说话更稳、更安全。

涌现能力指的是:某项能力在小模型上几乎看不到,但模型规模超过某个范围后,突然表现出来。典型例子包括多步推理、上下文学习、复杂指令理解、代码能力、跨语言迁移等。这也是为什么很多人觉得大模型“突然聪明了”。不是模型被显式教会了某个任务,而是当参数、数据和训练规模到达一定程度后,模型内部学到的模式足够丰富,开始能组合出更复杂的能力。涌现能力与评估指标有关,不能只看单一曲线。

可以把大模型想成一名刚读完很多书的新人。预训练让它见多识广,SFT 教它按照指令答题,但它还不一定知道哪种答案更受欢迎,也不一定能稳定处理安全边界、事实不确定和复杂要求。Post-Training 做的,就是继续纠正和塑造它的回答习惯。
PPO 的核心价值是在线探索。它让模型用当前策略不断生成新轨迹,通过奖励和优势函数学习,但也带来更复杂的采样、价值估计、KL 控制和稳定性问题。DPO 的核心价值是把偏好对齐压缩成一条更短、更稳定的训练链路。它无需显式奖励模型和 Value Model,容易接入现有微调框架,但学习边界更受离线偏好数据覆盖与质量限制。**真正的选择标准**不是“哪个算法更先进”,而是:你的奖励能否可靠计算、偏好数据

INT8 和 INT4 告诉我们模型用了多少位;GPTQ、AWQ、SmoothQuant 告诉我们如何降低精度;QLoRA 告诉我们如何在低比特基础权重上继续训练;GGUF 和 safetensors 则负责模型如何落盘。把这些层次分开,量化选型就不会只剩下“哪个文件更小”。真正可靠的方案,必须在自己的模型、硬件、框架和业务数据上同时验证质量、显存、延迟与吞吐。量化没有绝对冠军,只有更适合当前约束

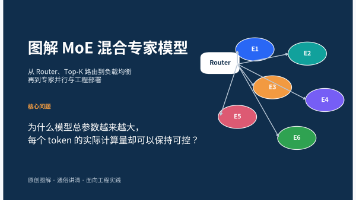
看到 DeepSeek-V3 的“671B 总参数、每个 token 激活 37B”时,很多人的第一反应是:这不是自相矛盾吗?模型明明有 6710 亿参数,为什么推理时只算 370 亿?答案就在 MoE(Mixture of Experts,混合专家模型)的核心设计:模型把 Transformer 中的前馈网络拆成许多“专家”,再由 Router 针对每个 token 只挑少量专家参与计算。模型容
大模型Agent是一个以大语言模型为“大脑”的自主系统。它能通过自然语言理解任务,进行复杂推理、制定计划,并结合记忆和工具来执行任务,还能多次迭代,最终实现用户设定的目标。如果说大语言模型通过千亿参数赋予了机器“最强大脑”,那么Agent则通过感知、规划、工具调用与记忆机制,为机器装上了“眼睛”“耳朵”与“手脚”,使其能够深入复杂的业务流程,从被动的信息生成者转变为主动的任务执行者。用短文本总结之