- @qiaoyuhanhan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器应用于特定的任务中。本章将使用迁移学习的方法对ImageNet数据集中的狼和狗图像进行分类。开始训练模型,与没有预训练模型相比,将节约一大半时间,因为此时可以不用计算部分梯度。,数据集中的图像来自于ImageNet,每个分类有大约120张训练图像与30张验证图像。使用固定特征进行

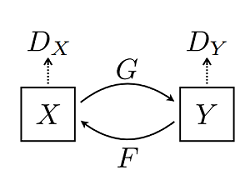
CycleGAN(Cycle Generative Adversarial Network) 即循环对抗生成网络,来自论文。该模型实现了一种在没有配对示例的情况下学习将图像从源域 X 转换到目标域 Y 的方法。该模型一个重要应用领域是域迁移(Domain Adaptation),可以通俗地理解为图像风格迁移。
DCGAN(深度卷积对抗生成网络,Deep Convolutional Generative Adversarial Networks)是GAN的直接扩展。不同之处在于,DCGAN会分别在判别器和生成器中使用卷积和转置卷积层。它最早由Radford等人在论文中进行描述。判别器由分层的卷积层、BatchNorm层和LeakyReLU激活层组成。输入是3x64x64的图像,输出是该图像为真图像的概率。

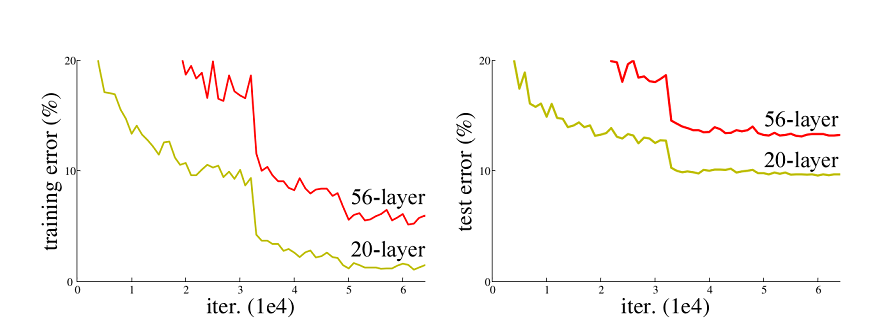
ResNet50网络是2015年由微软实验室的何恺明提出,获得ILSVRC2015图像分类竞赛第一名。在ResNet网络提出之前,传统的卷积神经网络都是将一系列的卷积层和池化层堆叠得到的,但当网络堆叠到一定深度时,就会出现退化问题。下图是在CIFAR-10数据集上使用56层网络与20层网络训练误差和测试误差图,由图中数据可以看出,56层网络比20层网络训练误差和测试误差更大,随着网络的加深,其误差
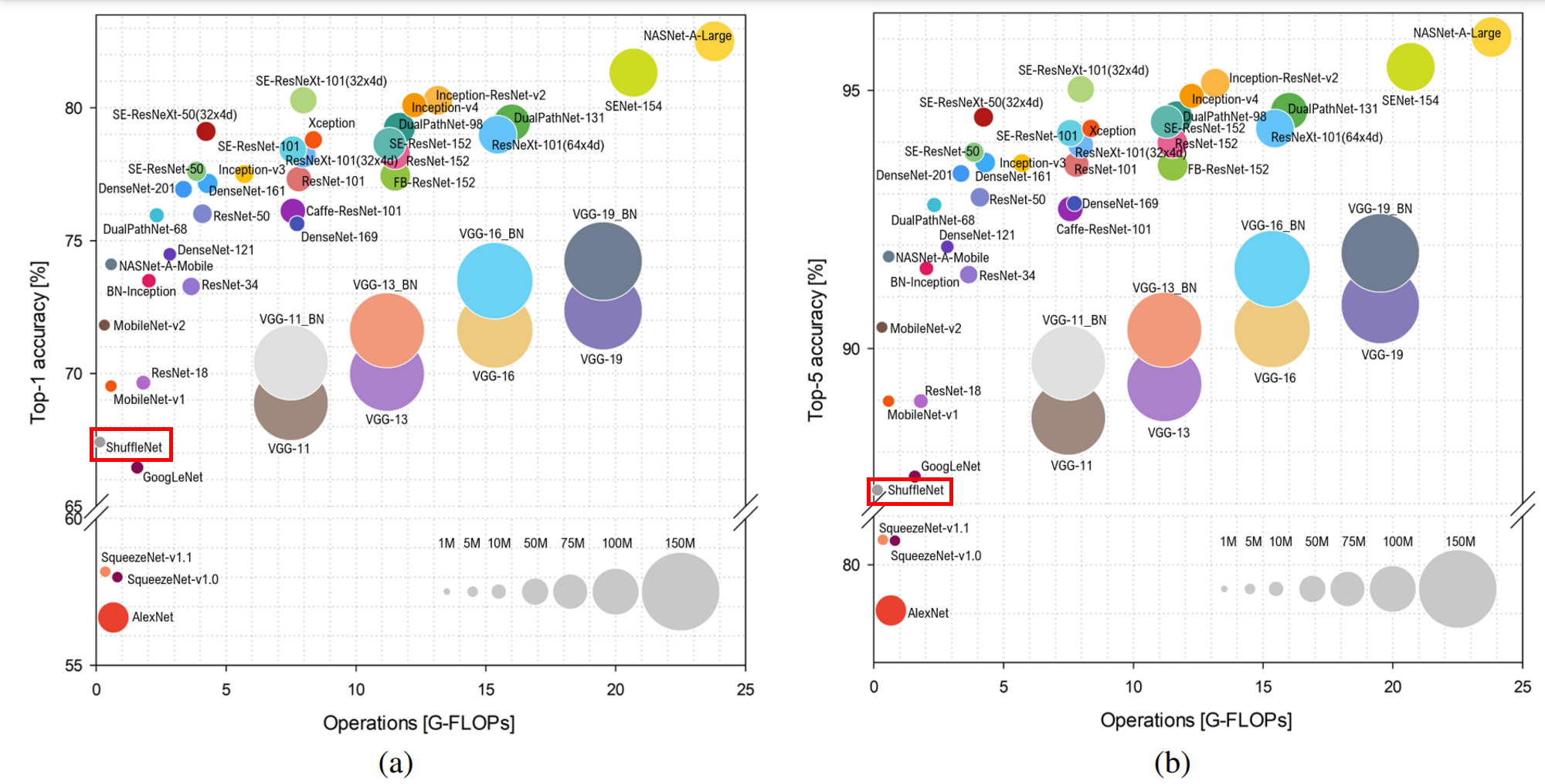
ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到最好的模型精度。ShuffleNetV1的设计核心是引入了两种操作:Pointwise Group Convolution和Channel Shuffle,这在保持精度的同时大大降低了模型的计算量。因此,ShuffleN
生成式对抗网络(Generative Adversarial Networks,GAN)是一种生成式机器学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。最初,GAN由Ian J. Goodfellow于2014年发明,并在论文生成器的任务是生成看起来像训练图像的“假”图像;判别器需要判断从生成器输出的图像是真实的训练图像还是虚假的图像。GAN通过设计生成模型和判别模型这两个模块,使其互相
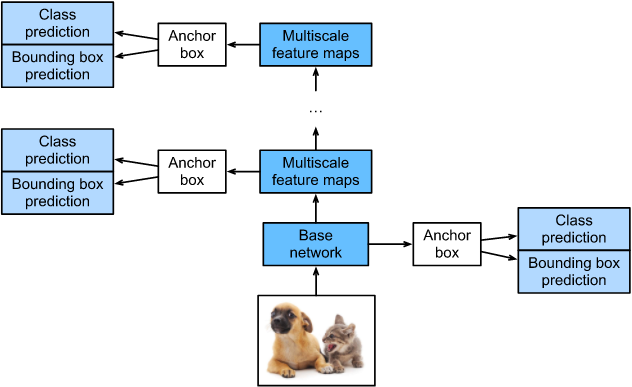
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster R
首先我们构造一个shape为(3, 28, 28)的随机数据(3个28x28的图像),依次通过每一个神经网络层来观察其效果。当我们定义神经网络时,可以继承nn.Cell类,在__init__方法中进行子Cell的实例化和状态管理,在construct方法中实现Tensor操作。construct意为神经网络(计算图)构建,用于定义要执行的计算逻辑,所有子类都必须重写此方法。方法不可直接调用。相关内
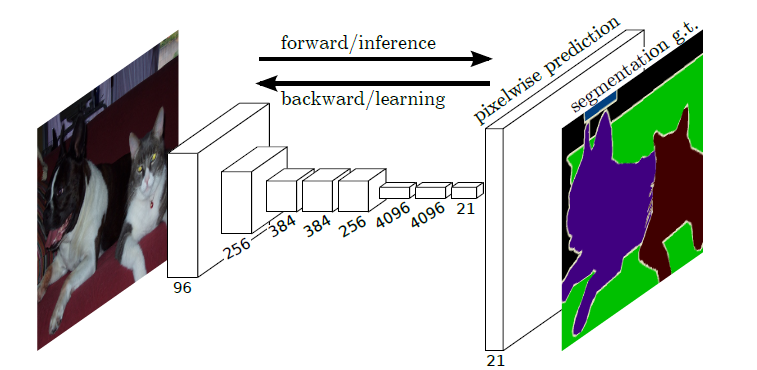
FCN主要用于图像分割领域,是一种端到端的分割方法,是深度学习应用在图像语义分割的开山之作。通过进行像素级的预测直接得出与原图大小相等的label map。因FCN丢弃全连接层替换为全卷积层,网络所有层均为卷积层,故称为全卷积网络。这一部分主要对训练出来的模型效果进行评估,为了便于解释,假设如下:共有k1k+1k1个类(从L0L_0L0到LkL_kLk, 其中包含一个空类或背景),pijp_{
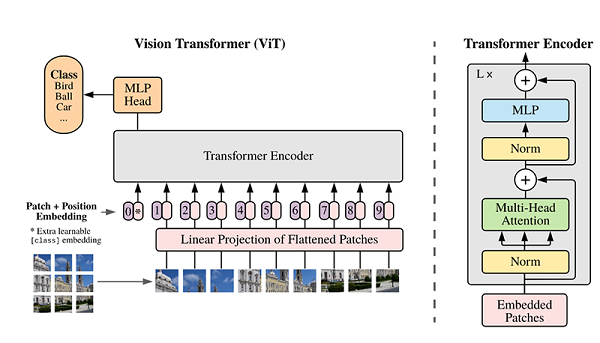
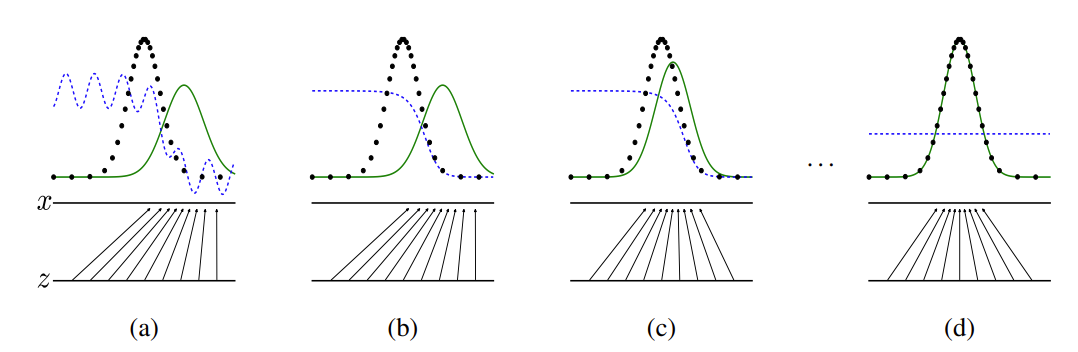
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大地促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。