




- @nenchoumi3119
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这个博客用来同步我们的一个开源工程,在 Jeston 设备上实现了 CUDA、TensorRT 的加速推理,利用 Yolo11 模型以及 Realsense D435i 运行了示例,其中的主要难点是编译模型虚拟环境。
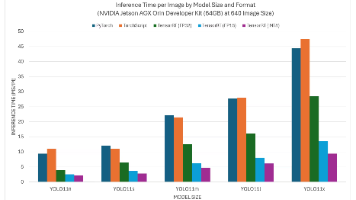
这个文档用来记录 Nvidia Orin DK Ubuntu 20.04 刷机 + CUDA TensorRT + 硬盘扩容 + ROS 安装 + OpenCV-CUDA + Ollama + Yolo11 一站式解决方案

这篇文章介绍了如何在本地运行,因为我使用的无人机是Tello,其本身仅提供了一个单目视觉相机,在众多单目视觉转 Depth 的方案中我选择了 Depth-Anything V2,这个库的强大在于其基于深度学习模型将单目视觉以较低的代价转换成 RGBD 图像,可以用来无人机避障与SLAM。

这个博客用来记录在 Nvidia Orin 64 GB DK 设备上本地 ollama 部署并评测主流的几个 20GB 以下模型 gpt-oss:20b、gemma3:27b、qwen3:30b 模型的性能,其中 gpt-oss 是 OpenAI 刚刚开源(2025年08月05日)的模型,距离博客形成时间(2025年08月07日)仅过去 2 天,算是赶了一个大早。
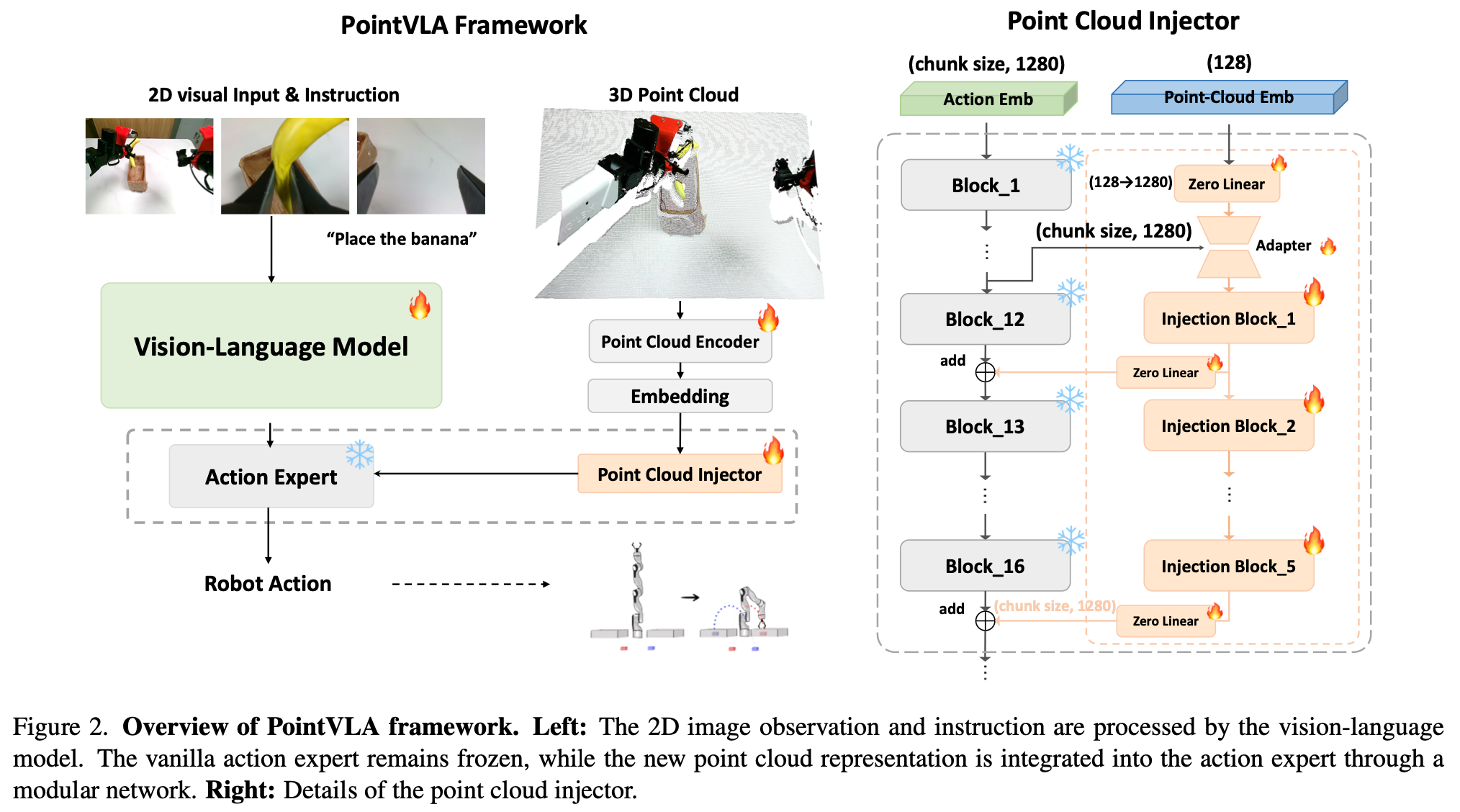
这篇文章最大的创新点在于将3D点云信息作为补充条件送入模型,而不是DP3一样只用纯3D数据从头训练模型,按照作者的说法这样可以在保留模型原有2D解释能力的同时添加了其3D能力,并且可以有效识别真实物体与2D照片,作者设置的各种任务中都超越了baseline模型。
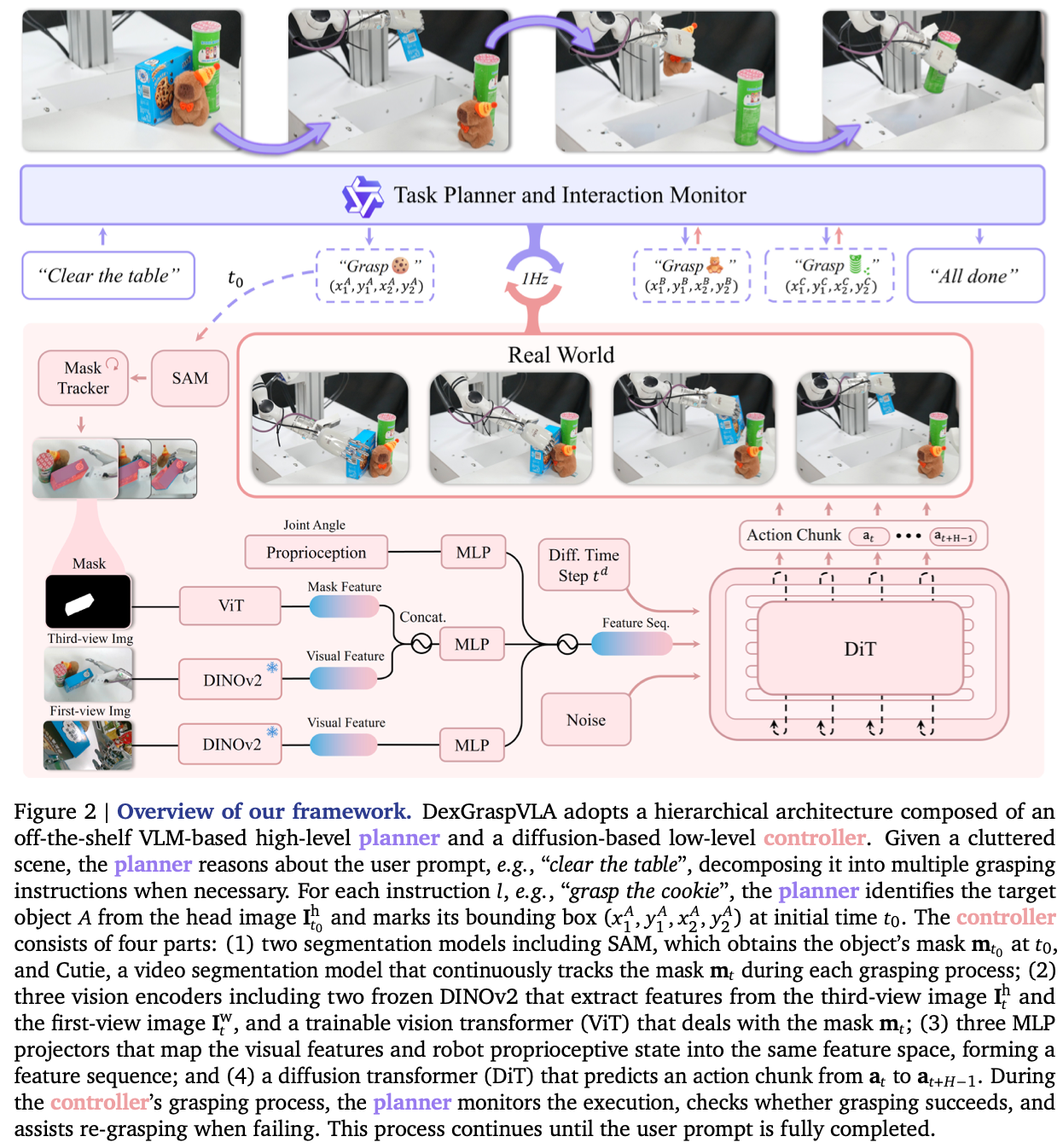
是一篇关于灵巧手抓取的VLA模型,并创建了一个开源数据集,尽管如此我还是觉得这篇论文内容不够丰满,特别是在模型对比上只和自己进行了消融实验,但文章中的实验却说明了其具备极强的泛化能力。
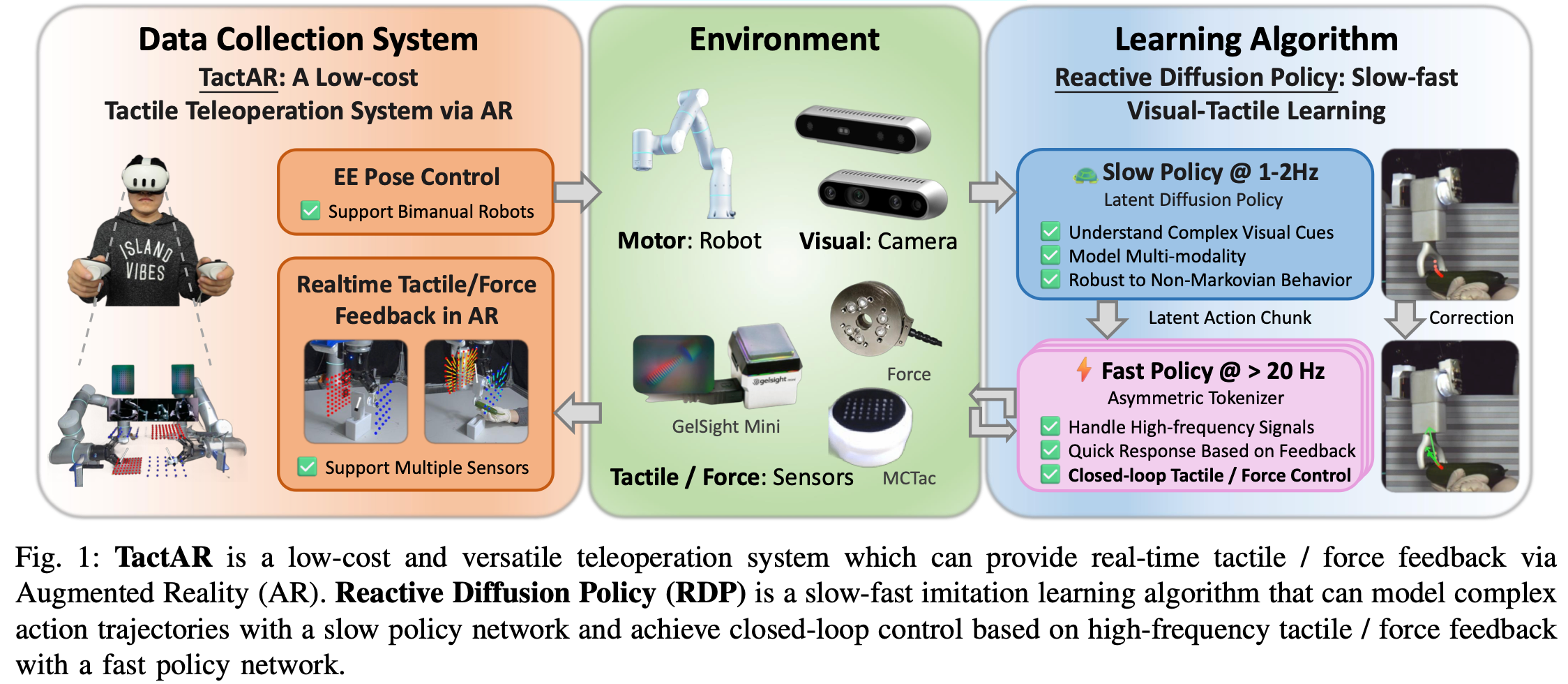
作者介绍了一个带有触觉信息的TactAR数据采集框架,并创造了一个RDP的快-慢策略网路,快网络用触觉信息实现闭环动作,慢网络用视觉信息提供开环轨迹。
这篇论文是 Nvidia 发表的一篇 VLA 领域的论文,提出了一个名为 VLA-0 架构,该架构采用了一种极其简单但被忽视的策略:将动作直接表示为文本 。它不需要对底层的 VLM 进行任何修改,将机器人的连续动作转换为数值字符串,然后像生成普通文本一样,训练 VLM 直接输出这些动作字符串。但想要实现这一效果还需要 Masked Action Augmentation、Ensemble Pred

这篇文章是对作者先前工作OpenVAL的一个扩展,旨在使用更好的微调方式以提高模型的控制输出频率,在这期间作者发现这种微调方式甚至能让模型获得更强大的泛化,包括双臂操作、多视角输入等。

这篇论文是2025年发表在arxiv上的一篇VLA领域论文,RDT也是做具身的一个必须了解的模型,和OpenVLA、$\pi0$ 这两个模型一样是基本功。
