




- @mnwl12_0
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
为企业制定决策、提供数据支持的,可以帮助企业改进业务流程提高产品质量等。DW不是数据最终目的地,而是为数据最终目的地做好准备,这些准备包括对数据的备份,清洗,转义、分类、重组、合并、拆分、聚合,统计等。是在数据库已经大量存在数据的情况下,一整套包括了ETL(用于描述将数据从来源端经过抽取、转换、加载到目的端的过程)、调度、建模在内的完整理论体系。

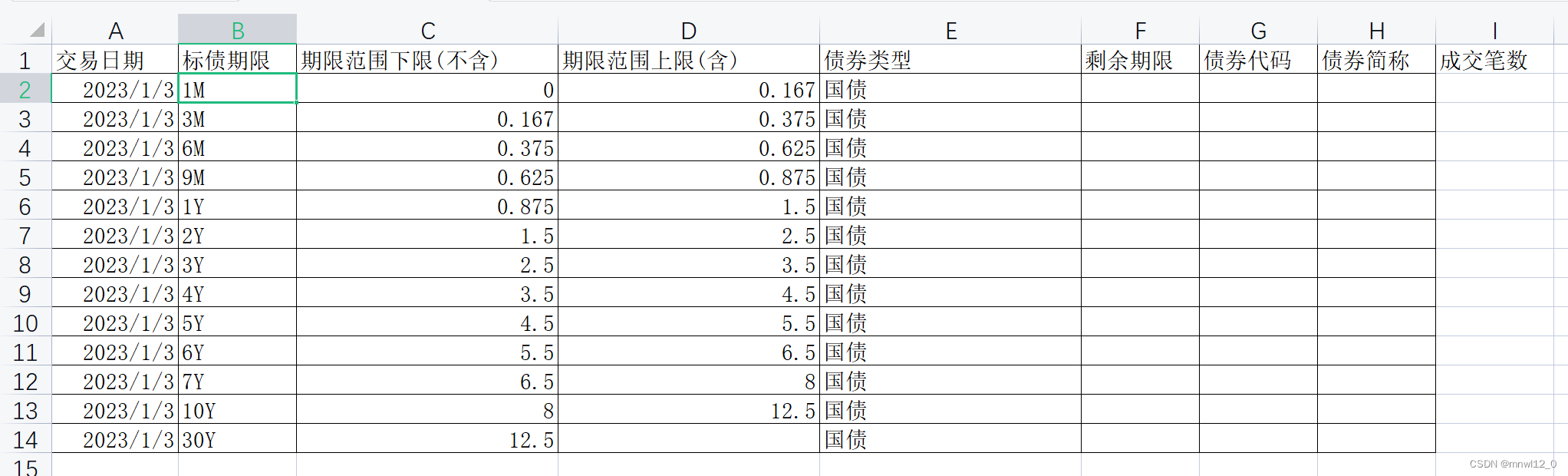
在Hive中,数据定义语言(DDL)是一种用于定义数据结构的语言,如表、分区和桶。创建表是使用DDL中最常见的任务之一。use test;id INT,创建一个名为employeesidnamesalary, 和department。这些字段分别被定义为整型(INT)、字符串(STRING)、浮点型(FLOAT)和字符串类型(STRING)。此表使用逗号作为字段分隔符,并以文本格式存储。表创建后,

如果表的列名和表格的列名不一致会发生(如列名ID不一致,表的列名为ID,表格列名为:“代码”),ID列为NULL,且在表的最后一列会生成“代码”一列,后面做运算极其麻烦,要规避这种情况,到这里数据导入部分结束了。先读取3个文档,然后按行拼接数据,再按日期进行排序,原始数据是很乱的,有可能倒序,最后输出成csv格式,输出后的格式为:25000多行,首先需要对原始数据进行处理,把不同表格数据进行拼接在
来逐步逼近C的最小值,也就是先随机得到一组参数变量的值,然后计算参数变量当前的梯度,向梯度的反方向,也就是C变小最快的方向,逐步调整参数值,最终得到C的最小值,或者近似最小值。为了降低推导的复杂性,我们只计算相对于一个样本的损失值函数Cbi的偏导数,因为相对于总损失值函数C的偏导数值,也不过是把某个参数的所有相对于Cbi偏导数值加起来而已。我们需要的是,调整参数,使得所有输入样本,得到输出的总损失


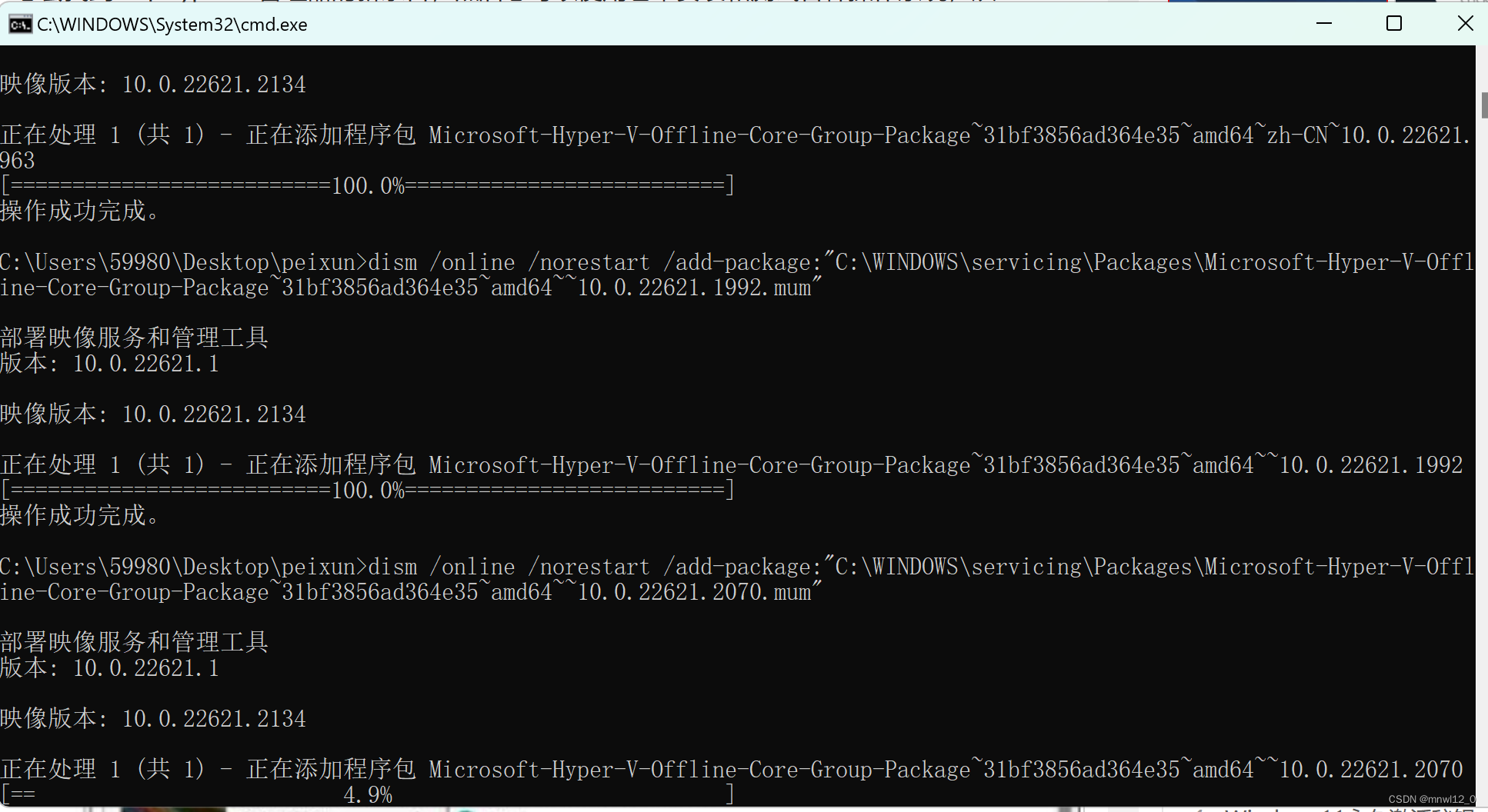
将文档另存为批处理文件(单击File > Save As,从Save as type下拉菜单中选择All Files (*.*),然后在File name框中键入 hv.bat — 尽管它是 .bat重要的部分;您可以使用任何您喜欢的名称)。注意:如果您没有在“开始”菜单中看到 Hyper-V 管理器,请打开“设置”并前往“应用程序”。查看“开始”菜单,您会找到一个Hyper-V 管理器的新条目,

在统计学中,MAD是对单变量数值型数据的样本偏差的一种鲁棒性测量,即是用来描述单变量样本在定量数据中可变的一种标准。MAD(median absolute deviation)绝对中位差。

此外,还提到了其他相关的异常点检测方法。这些弱的检测器可能是简单的模型或者规则,它们的个体性能可能并不出色,但通过集成它们的结果,Loda能够获得与更复杂方法相似的错误率,并且在性能上能够超过当前的先进方法。摘要(Abstract):介绍了Loda系统的背景和目标,强调了它是一个轻量级的在线异常点检测器,可以在实时处理大量样本的领域中使用,并能够处理数据流中的概念漂移和缺失变量问题。因此,Loda
