




- @m0_71745903
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
机会,永远属于有行动力的人。如果从未起步,你永远不知道,AI 能带给你什么改变。直到翻到 2023 年的那一页,我忽然明白了。那个第一次经历职场失意,一度迷茫的我,与横空出世的大模型不期而遇。从此,我的人生开始和 AI 协作,开启了一段不可思议的旅程。和它协作去学习,一年看了 60 本书;和它协作促身体,一年减脂 70 斤;和它协作做创作,半年积累 100 个场景提示词。没有代码经验的我,在 20

软件测试常问100道面试题,找工作、招人必备之良品。后期不断完善中……
Stable Diffusion 大概是时下最流行的两个项目之一,另外一个就是大名鼎鼎的 ChatGPT ,AI绘图现在已经是非常成熟,相信很多做设计的小伙伴都知道 Stable Diffusion ,只需要描述一段文字,它就能帮你生成一张图片。当你还在花费大量时间埋头创作时,Stable Diffusion一分钟不到就能生成大量作品。

Hashcat 是一款用于破解密码的工具,据说是世界上最快最高级的密码破解工具,支持 LM 哈希、MD5、SHA 等系列的密码破解,同时也支持 Linux、Mac、Windows 平台。工具地址:https://hashcat.net项目地址:https://github.com/hashcat/hashcat。
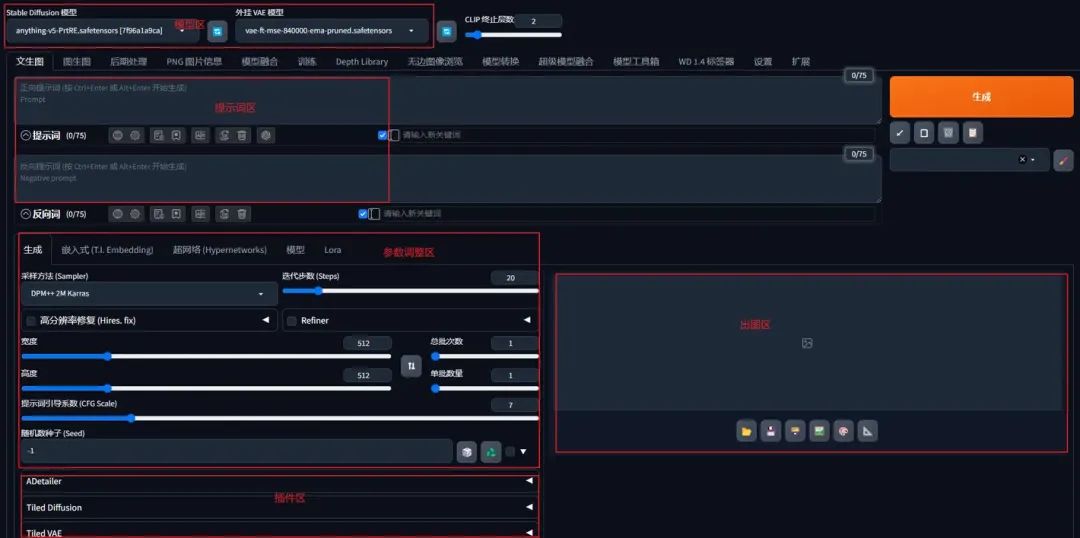
大家好,在上一篇中我们成功安装了Stable diffusion软件,而今天,我们将深入了解Stable diffusion的文生图功能,让你也能生成满意的图片!如上图,这是Stable diffusion的文生图界面,这个界面总体可以分为五个区域:模型区:调整/更换模型的地方提示词区:撰写提示词的地方参数调整区:调整模型参数的地方插件区:SD的各种插件出图区:就是展示生成图片的地方。
目录模型生成效果展示(prompt 全公开)如何注册 Stable Diffusion 使用SD(dreamstudio.ai )的收费标注如何SD 提供哪些参数可以设置如何使用种子来改进一张作品我用 SD 创作的图片著作权如何归属,可以拿来商用吗?Stable Diffusion 背后的研发团队SD 是如何训练出来的?SD 是开源的吗?SD 未来有哪些可期待的亮点附录:文末获取StableDif

在 Stable Diffusion 的广袤创意宇宙中,选对模型如同握有开启特定风格大门的钥匙。今天,我们将深入剖析三款热门模型 ——majicMIX realistic v7、ReV Animated v1.2.2 与 Counterfeit - V3.0,搭配丰富实例,助你精准拿捏不同风格创作。模型特色majicMIX realistic v7 堪称写实风格领域的佼佼者,对细节的雕琢达到了令人

前段时间 GPT-4o 的【吉卜力】图像风格化,真的是火出天际,那如何给 DeepChat 也添加此能力呢?【吉卜力】图片风格化,本质还是图生图,而大模型的 function call 不能直传图片 base64,否则 token 会爆。所以与 MCP Server 交互,涉及图片最好使用 URL 或文件路径,本例使用的就是文件路径。需要特别说明一下,DeepChat V0.0.15 版本后,才能
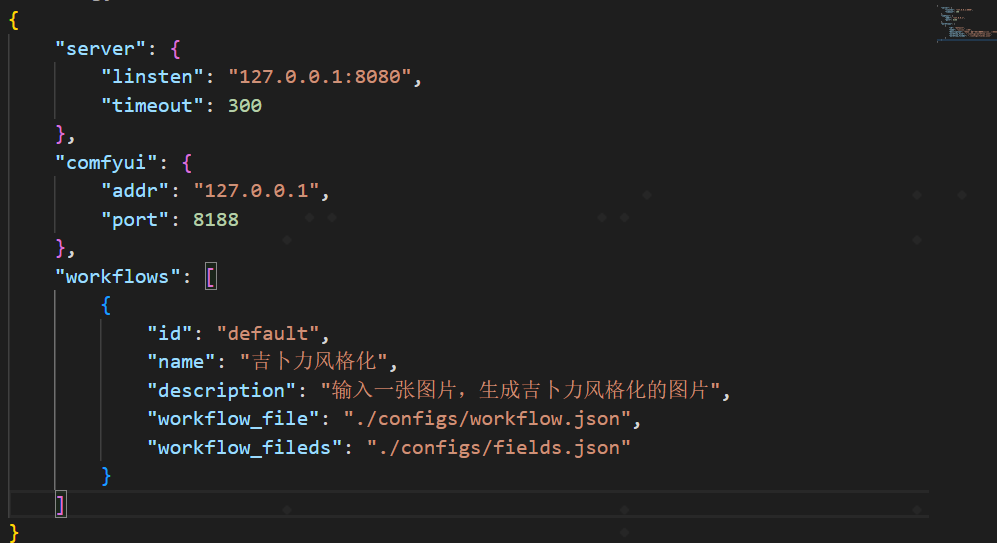
LoRA模型是一种用于微调大型生成模型(如Stable Diffusion)的高效技术。它通过在预训练模型的基础上引入可训练的低秩矩阵,仅调整部分参数,而非重新训练整个模型,从而以较低的计算成本实现特定任务的优化。与类似SD1.5这样的大模型相比,LoRA模型更小、更容易训练。Load Lora节点位于的模型会被ComfyUI检测到,并在这个节点中加载。

Stable diffusion的模型除了上述的分类之外,从用途上看,还分为官方模型、二次元模型(动漫)、真实系模型和2.5D模型四大类。4.1 官方模型官方模型有 1.X 和 2.X 两个大版本,目前在 1.X 中官方发布的有四个版本,分别是v1-1、v1-2、v1-3、v1-4。
