




- @m0_69194031
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
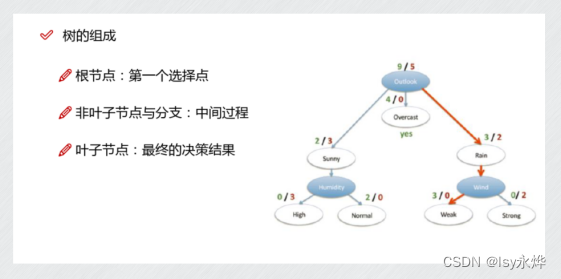
与此关联的是C4.5,选信息增益率最大的作为下一个节点,使用该方法最大的优点就是避免了因为种类太多导致gain值过于大的情况(分母越大,值越小)。2.根据提供的打球和天气表格构造决策树,要求计算每个特征的信息熵(4分),并依据信息增益确定每个根节点的特征(3分),画出决策树(3分)。的方法,每次都把当前样本集划分为两个子样本集,使生成的决策树的结点均有两个分支,显然,这样就构造了一个。(1)蓝的是
19. 聚类的目的是对样本集合进行自动分类,以发掘数据中隐藏的信息、结构,从而发现可能的商业价值。8.聚类(Clustering):对无标签样本的相似度进行度量,挖掘特征、结构、内在性质,使类内相似度大,类间相似度小。9.输出结果(预测值)与其对应的真实值之间往往会存在一定的差异,这种差异被称为模型的输出误差,简称为误差。5.特征向量(Feature Vector):每个样本的特征 对应的特征空间
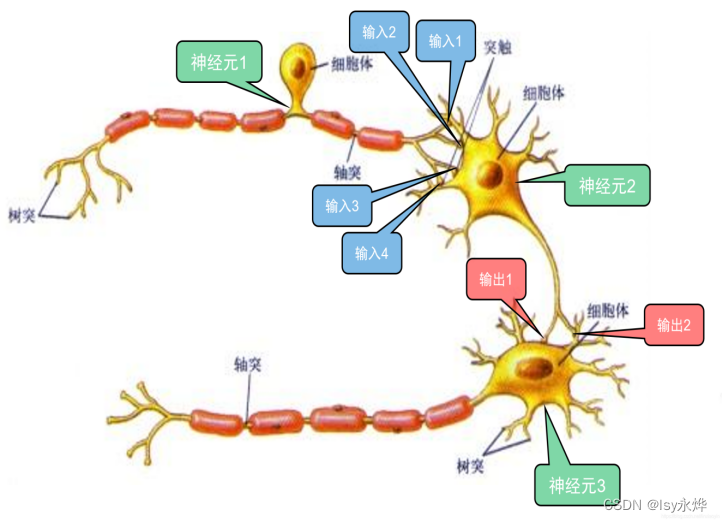
例如:假设你是一只小蚂蚁,你的任务是找小面包。你的视野还比较窄,只能看到很小一片区域。当你找到一片小面包之后,你不知道你找到的是不是全部的小面包,所以你们全部的蚂蚁开了个会,把所有的小面包都拿出来分。反向传播(Backpropagation,BP)算法。输入信号之和超过神经元固有的边界值(阈值)(一定要看,弄懂权重w,和输入a是什么)避免了对图像的预处理和显示的特征提取。对于信息位置与方向变化不敏
它能检查出并报告一些基本的差错,在一定程度上给出出错原因,还可以让一个路由器向其它路由器或主机发送差错或控制报文,ICMP在两台机器上的Internet协议软件之间提供了一种通信方式。11.采用距离矢量路由选择算法进行路由选择,可以做到通过各节点之间的路由信息交换,每个节点可获得全网的拓扑信息。在该路由器中,路由表再次为远程主机或网络查询路由,若还未找到路由,该数据包将发送到该路由器的缺省网关地址

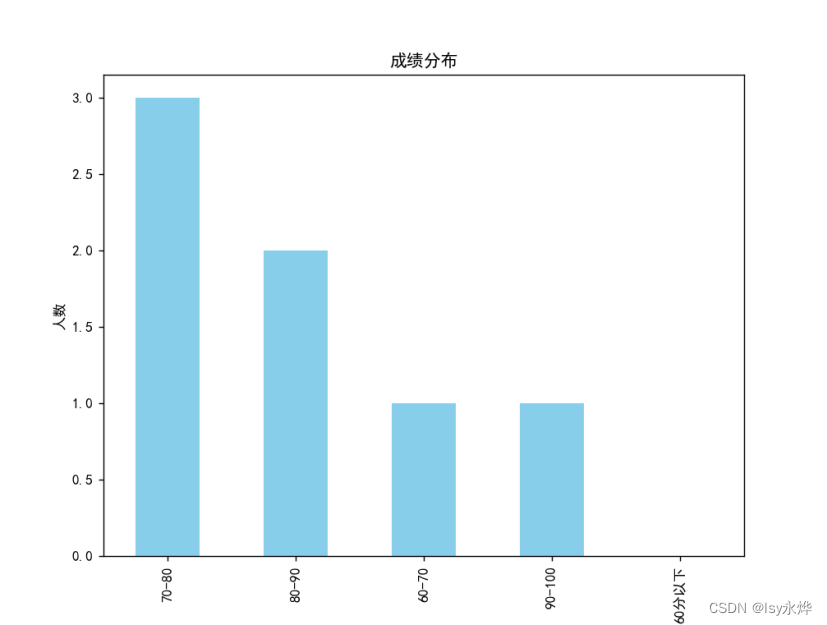
(1)掌握数据表示与获取;(2)掌握pandas数值运算操作;(3)根据运算结果,使用Matplotlib绘制图表;(4)通过设计型实验的方式,掌握数据统计分析的方法和技术,理解数值计算和数据可视化在数据分析过程中的意义和作用,提高学生解决复杂数据统计分析问题的能力和素养。
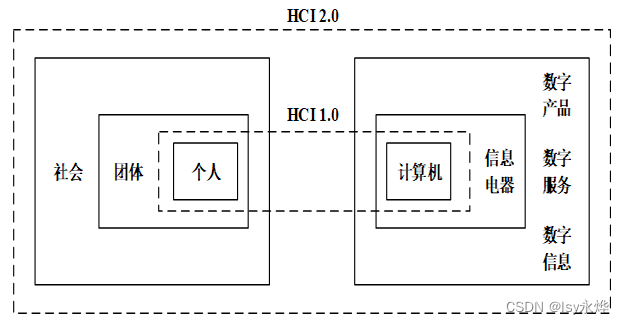
(4)从人性角度看:每个人都会犯错,如果一个交互系统不能帮助用户有效地降低错误发生的概率,那么由此引发的时间、金钱以及生命的损失都是难以估量的。人机交互的知识点碎,而且都是文字,过一遍脑子里什么都留不下,但是背时间已经来不及了,最好还是找题要题感吧,加深印象才是做对文科的关键。(4)HCI 2.0:规定的范围得到了拓展,它特指从2000年年末开始流行的Web 2.0环境下的人机交互。(2)可划分为
(1)因为是假设用户完全按正确的方式进行人机交互,缺乏对错误处理过程的清晰描述。(3)即,如果我们知道一个动作的难度和执行该动作的速率,通过计算(难度/速率)来得到表示人类执行能力的值。M K[i] K[p] K[c] K[o] K[n] K[f] K[i] K[g] K[回车]有的人成功了,他把这一路的经验中可以供其他人参考的部分总结了出来,然后让别人套用。(1)这个时间是研究总结平均时间,实际

C语义编码是长时记忆的最主要的编码方,它是按言语发生的顺序以系统方式来表征信息的D长时记忆的信息编码是把新的信息纳入已有的知识框架内,或把一些分散的信息单元组合成一个新的知识框架。1.关于执行评估活动周期模型(EEC):①执行动作,②解释系统状态,③评估,④感知系统状态,⑤形成操作意图,⑥形成操作序列,⑦建立目标,以下哪个步骤排序是。D长时记忆的信息编码是把新的信息纳入已有的知识框架内,或把一些分
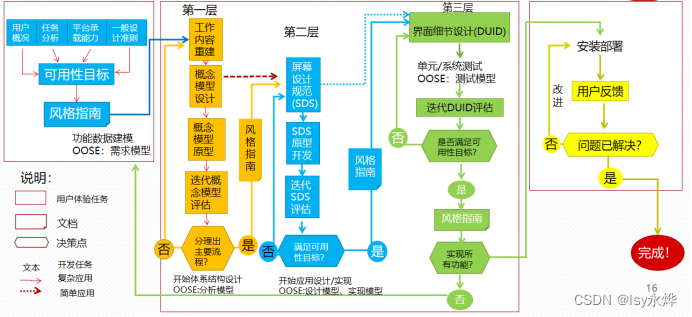
通俗的说就是一个景区那种指南,针对一个主题,把谁在哪些地方,该做什么、不该做什么、甚至是怎么做都列出来,形成一套共识体系,新人可以学习,老人可以参考,最后解决一致性问题。LUCID(合理的以用户为中心的交互设计),属于交互设计过程管理的一部分,记住本题即可。候选设计方案是有限的,来源于个别设计人员的才干和创造力,也来自考虑其他相似的设计。c.三级(涉众)用户:引入系统会影响到的人员以及影响系统购买
这部分详细解释会很复杂,主要还是看当初小组作业大家设计的过程,或者就看结果,到时候出了知道怎么编故事就行了,肯定能混到分的。由于人物角色和真人是相似的,将他们和真人联系起来,要比把功能列表、流程图和真人联系起来更容易。(3)专家用户:对缺少经验的用户有着异乎寻常的影响,即“专家说不好就不好”(1)拼凑:采用头脑风暴方法,产生一些零碎片段,先不去考虑他们的细节。就是编故事,其中编的主角,编的这个小故
