




- @m0_64752471
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近国产大模型KIMI爆了大部分人应该都知道了,从我个人的感受来看这次KIMI爆了我不是从技术领域接触到的,而是从各种金融领域接触到的。目前国内大模型可以说是百模大战,前几年新能源大战,今年资本割完韭菜后留给我们的是一家家倒闭或者即将要倒闭的车企,今年有一句话听了让人非常的无奈:“如果前几年你买了房子,又买了车子,你不仅要担心你的房子什么时候会爆雷还要担心你的车子什么时候会爆雷”。过几年大模型爆雷

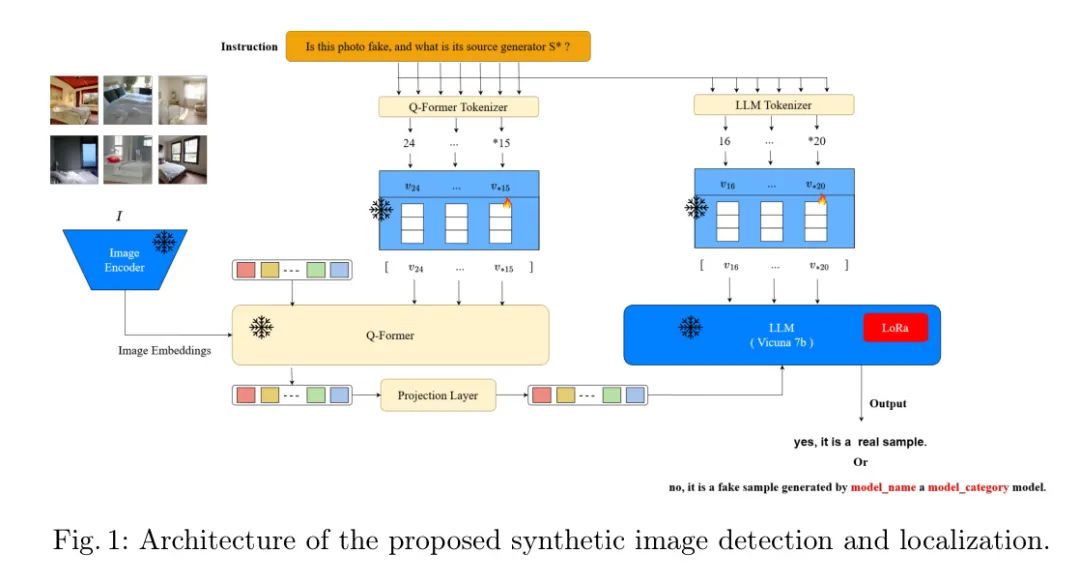
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】在过去的二十年里,生成和编辑照片的技术发生了迅速的变化。这一变化带来了视觉内容可以轻松创建和编辑的时代,留下了极少的感知痕迹。因此,人们逐渐意识到作者正站在一个真实图像与计算机生成图像难以区分的世界的边缘。最近生成模型的发展进一步推动了合成图像的质量和高保真度,使它们
在半年前,锅头只是从表面上浅浅地了解AI的到来,铺天盖地的AI资讯,还有各种贩卖AI焦虑的内容,自己也会产生焦虑。它能带来哪些效率提升?既然我已经花了这么多时间学习、收集、体验、整理、思考,那么是不是可以挑选出有价值的AI内容分享给和我一样有过AI焦虑、现在希望学习AI的人?在学习AI之前,咱们最好能简单了解AIGC的基础知识,对AIGC有初步认知,以便后续使用AI工具时能更好地了解它的应用场景。
今天给大家分享一下,从面试官的视角看,什么样的简历算一份优质的简历?以及如何快速把简历改好。为什么想讲这个呢?因为最近我也在集中面试嘛,看了 N 多份简历,大部分人的简历写的,就两个字,。首先简历不是向别人介绍你的过去,也不是工作学习总结。它是要体现你的核心竞争力,你和别人不一样的地方。所以很多人出发点就错了,把简历写成了。然后简历上最重要的就是项目嘛,项目编写的一个常见 badcase,就是记流

大模型发展实在是太快了,也太“卷”了,在ChatGPT发布大火之后,标志着人类开始已经进入大模型时代… 在这里时代了主要围绕大模型本身(参数,打榜)、多模态(视频、声音)、Agent(自动化)、提示词工程、RAG、微调等“生态”展开…转眼之间,这些东西已经“卷”了不知道多少轮了,随着荣耀CEO演示通过语音助手直接调用美团APP实现点咖啡的演示,到Claude 3.5 Sonnet-20241022

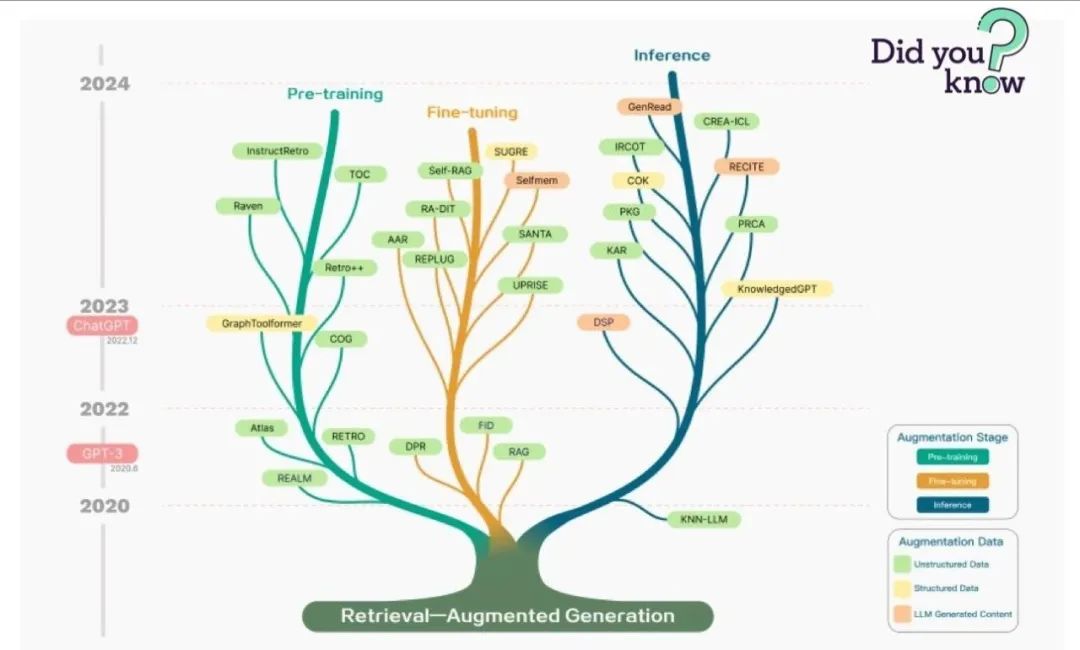
RAG即检索增强生成,为 LLM 提供了从某些数据源检索到的信息,并基于此修正生成的答案。RAG 基本上是 Search + LLM 提示,可以通过大模型回答查询,并将搜索算法所找到的信息作为大模型的上下文。查询和检索到的上下文都会被注入到发送到 LLM 的提示语中。嵌入式搜索引擎可以通过 Faiss 来实现,向量搜索领域成为了RAG的一个助力。像pinecone 这样的。
在当前信息时代,大型语言模型(Large Language Models,LLMs)的发展速度和影响力日益显著。大模型强大的推理以及生成能力成为了搭建智能体的最好的组件。本内容来源于Datawhale的开源的“生成大模型基础(so-large-lm)”,一个致力于探索和理解大型模型发展的前沿课程:https://github.com/datawhalechina/so-large-lm通过该开源课
在 OSWorld 这项测试模型使用计算机的能力的评估基准上,Claude 当前的准确度为 14.9%,虽然远远不及人类水平(通常为 70-75%),但却远高于在此基准上排名第二的 AI 模型(7.8%)。该公司举了个例子:如果用户是一名开发者,使用的软件有好几个,同时也已经给予了 Claude 适当的权限,那么 Claude 就可以查看用户能看到的屏幕,然后统计其所要移动的垂直和水平像素的数量,
RAG 技术是一种检索增强生成的方法,结合了大型语言模型和检索系统的优势,以提高生成内容的准确性、相关性和时效性。相比于仅依赖大型语言模型的生成,RAG技术可以从外部知识库中检索信息,避免了模型的幻觉问题,并提升了对实时性要求较高问题的处理能力。与传统的知识库问答系统相比,RAG技术更加灵活,可以处理非结构化的自然语言文本。RAG并非旨在取代已有的知识库问答系统,而是作为一种补充,强调实时性和准确

OpenAI o1(后面简称o1)是OpenAI在2024.9.12号发布的最新大模型,主要针对的任务是复杂任务推理,比如竞赛难度的编程问题,奥赛难度的数学问题等。为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
