- @m0_62491477
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
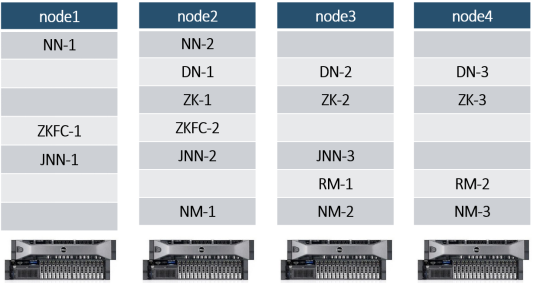
Hadoop是一个开源的分布式系统基础架构,由Apache基金会开发,用于可靠、高效地存储和处理海量数据。其核心组件包括HDFS(分布式文件系统)、YARN(资源管理)和MapReduce(计算框架)。Hadoop生态圈包含多个关联项目如Hive、Spark、HBase等,支持多样化的大数据处理需求。Hadoop 3.x版本带来了多项改进,包括纠删码存储优化、多NameNode容错、端口冲突解决等
本文介绍了Hive中常用的内置函数分类及使用方式,包括数学函数、收集函数、类型转换函数、日期函数、条件函数、字符串函数、聚合函数和表生成函数。重点演示了通过内置函数实现WordCount统计的完整流程,以及开发自定义UDF函数对手机号进行脱敏处理的具体实现步骤。文章提供了丰富的函数语法示例和使用场景,帮助读者掌握Hive函数的核心功能与应用技巧。

本文介绍了Hive SerDe、Hive参数、Hive的运行方式(CLI/脚本)、Hive视图、公共表达式、索引、Hive优化

本文介绍了使用Java API操作HBase数据库的基本方法。首先搭建HBase集群环境并创建Maven项目,添加HBase依赖。通过Connection对象建立与集群的长连接,并演示了Admin管理操作,包括创建/删除命名空间、判断表存在性、创建/删除表等核心功能。文章详细展示了数据操作API,包括put添加数据、get查询单条数据、scan范围扫描以及delete删除数据的方法实现,每个操作都

HBase读写流程采用分布式架构,客户端通过Zookeeper定位元数据表(hbase:meta)位置,缓存Region信息后直接与目标RegionServer交互。写流程通过WAL日志和MemStore实现数据持久化,定期刷写为HFile文件,并自动进行Minor/Major合并优化存储。读流程优先查询BlockCache和MemStore,未命中则读取磁盘文件。表设计强调反范式化,通过冗余列族

Flume是一个分布式、高可用的日志采集系统,用于高效收集、聚合和传输海量日志数据。其核心架构由Source、Channel和Sink组成,支持多种数据源和存储目的地。Flume提供Exec Source、SpoolDir Source和Taildir Source等采集方式,其中Taildir Source兼具实时性和可靠性。在数据输出方面,Flume支持HDFS、Hive和HBase等多种Si

HBase基于Hadoop HDFS构建,支持海量数据的实时读写。它采用列式存储,可轻松处理百亿行级别的数据,解决了传统关系型数据库在扩展性上的瓶颈。HBase架构包含RegionServer、Master和Zookeeper等组件,通过自动分片和负载均衡实现高可用性。相比MySQL分库分表方案,HBase具有自动扩容、高效列查询和历史数据版本管理等优势,特别适合大数据场景下的随机读写需求。其数据