- @m0_59012280
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenAI 开展了一项极端实验:五个月内完全依靠 Codex Agent 开发百万行级产品,效率达传统模式十倍,并提出用于管控 AI 编码的 Harness 工程体系。在 Agent‑First 研发模式下,人类工作从编写代码转向架构设计、环境构建与反馈闭环搭建。团队放弃臃肿文档,改用轻量化、可导航、可自动校验的结构化文档体系;针对 Agent 易模仿坏模式、代码碎片化问题,构建刚性架构约束与自

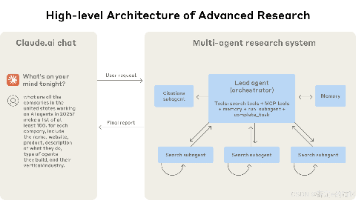
Anthropic构建的多智能体研究系统采用Orchestrator-Worker架构,将研究任务拆解为全局决策和局部探索两部分。该系统通过并行处理扩大信息覆盖范围,性能提升主要源于Token容量的扩张而非单纯推理能力。研究发现:复杂研究任务需要动态分工和反复调度,单智能体模式难以应对开放式、路径依赖的研究特性。系统采用Claude Opus担任编排者,多个Sonnet作为子智能体的组合方式,并强
本文梳理了AI科研与量化投资领域的关键开源工具,涵盖计算机和金融两大方向。在通用科研工具方面,推荐Semantic Scholar、Zotero和RAGFlow等文献检索管理工具;计算机领域重点介绍AI-Researcher、STORM等自主科研Agent和OpenHands代码实验辅助工具;金融领域则聚焦FinGPT金融大模型和FinRobot分析平台。文章还针对不同研究场景给出具体选型建议,如
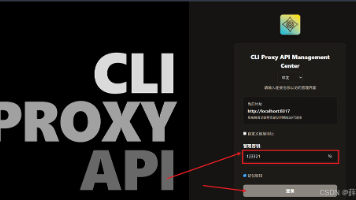
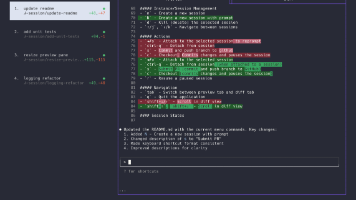
本文介绍了如何快速搭建和使用CPA(CliProxyAPI)服务来共享codex账号。主要内容包括:下载并解压CPA程序、配置config.yaml文件(需修改默认API密钥)、启动服务并通过浏览器管理界面导入.json认证文件。最后以Cherry Studio为例,演示如何将本地CPA服务作为OpenAI提供商接入,并补充了ccswitch配置说明。全文提供了详细的操作步骤和配图指引,适合新手快
2025年起,AI编码工具从单代理转向多代理协作成为关键趋势。本文评测了7个解决Claude Code与Codex CLI协作问题的开源项目: agor - 功能最全面的多代理操作系统,提供可视化画布和MCP通信,适合团队基础设施 claude-squad - 最均衡的终端管理器,使用tmux+git worktree隔离,适合快速上手 myclaude - 方法论导向的工作流框架,提供路由编排和
Supabase作为25年后端热门开源BaaS框架,GitHub星标98000+,基于PostgreSQL封装全套后端基础设施,支持用户认证、文件存储等核心功能,可云服务快速上手或Docker本地部署。本文实操演示Supabase云服务使用、Navicat远程连接、前端SDK接入及RLS行级安全策略配置,同步详解PostgreSQL核心特性,包括自定义类型、表继承、JSONB支持、全文检索及高级索
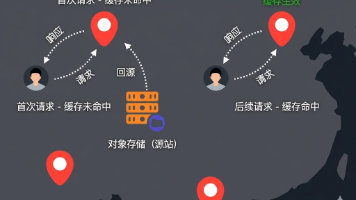
文章摘要 CDN、反向代理与边缘函数 CDN是一种分布式内容分发网络,通过就近节点访问资源降低延迟。实际工程中采用"源站-缓存-回源"的被动缓存模型,而非全量推送。CDN本质是带缓存的反向代理集群,包含就近调度、多级缓存等功能。边缘计算将函数计算部署到CDN节点,实现低延迟处理,可用于图片防盗链等场景。 Cloudflare免费服务汇总 Cloudflare提供多项免费服务:1)无限流量的CDN和
本文介绍了如何快速搭建和使用CPA(CliProxyAPI)服务来共享codex账号。主要内容包括:下载并解压CPA程序、配置config.yaml文件(需修改默认API密钥)、启动服务并通过浏览器管理界面导入.json认证文件。最后以Cherry Studio为例,演示如何将本地CPA服务作为OpenAI提供商接入,并补充了ccswitch配置说明。全文提供了详细的操作步骤和配图指引,适合新手快
文章摘要 CDN、反向代理与边缘函数 CDN是一种分布式内容分发网络,通过就近节点访问资源降低延迟。实际工程中采用"源站-缓存-回源"的被动缓存模型,而非全量推送。CDN本质是带缓存的反向代理集群,包含就近调度、多级缓存等功能。边缘计算将函数计算部署到CDN节点,实现低延迟处理,可用于图片防盗链等场景。 Cloudflare免费服务汇总 Cloudflare提供多项免费服务:1)无限流量的CDN和
摘要 工程变更传播分析研究设计变更如何沿产品、流程和组织网络扩散,涉及多学科交叉方法。本文梳理了关键研究路线:基于DSM/复杂网络建模传播路径,利用多智能体仿真动态模拟变更扩散过程,并通过优化算法选择控制方案。推荐了必读文献(如2022年综述和2017年多智能体方法论文)及开源工具链(Mesa、NetworkX、PuLP等),为构建可复现的研究原型提供路线图。研究重点在于将静态网络分析、动态仿真与