
写文章




- @m0_58678659
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
【论文笔记】Vision Transformer for Small-Size Datasets
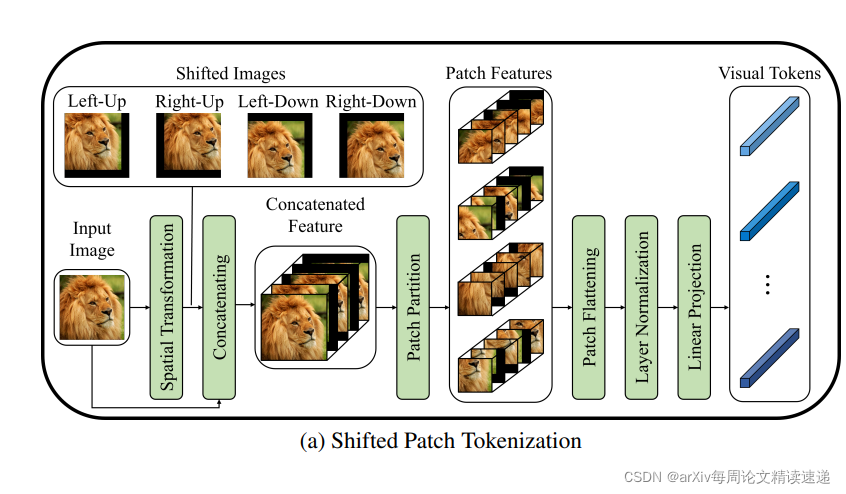
论文标题:Vision Transformer for Small-Size Datasets论文链接:https://arxiv.org/abs/2112.13492论文代码:https://github.com/aanna0701/SPT_LSA_ViT发表时间:2021年12月创新点由于 ViT 的高性能源于使用大数据集进行预训练,并且其对大型数据集的依赖被解释为由于低局部归纳偏差,因此本文
【论文笔记】IEEE | 一种新卷积 DSConv: Efficient Convolution Operator
我们引入了一种称为 DSConv(分布移位卷积)的卷积层变体,它可以很容易地替换到标准神经网络架构中,并实现更低的内存使用和更高的计算速度。DSConv 将传统的卷积核分解为两个组件:可变量化核 (VQK) 和分布偏移。通过在 VQK 中仅存储整数值来实现更低的内存使用和更高的速度,同时通过应用基于内核和通道的分布偏移来保留与原始卷积相同的输出。我们在 ResNet50 和 ResNet34 以及

linux系统 anaconda 换源操作命令
linux系统anaconda 换源问题
到底了