




- @m0_57790267
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
维度Eager Mode执行方式解释执行,遇操作即运行先捕获图,编译优化,再运行速度基准速度通常更快(融合算子,减少开销)调试非常方便(printpdb较复杂(优化后的代码不易直接调试)内存占用基准占用通常更低(算子融合减少中间变量)启动时间无预热时间有一次性编译预热时间适用场景开发调试、动态性强的小模型生产部署、训练大模型、固定结构的推理。
输入 sudo apt install ubuntu-restricted-extras。按住 ctrl+alt+T 打开终端。来解决ubuntu许多受限问题。

它在回归问题中用于特征选择,有助于识别对目标变量有重要影响的特征,同时将不相关的特征的权重收缩为零。L1正则化的效果是使一些权重趋向于零,从而使模型更加稀疏,即某些特征对模型的预测贡献较小,这有助于特征选择和减小模型的复杂度。L1约束(L1 constraint)通常是指在机器学习和优化领域中,对模型的权重(参数)添加L1正则化项,L1正则化项也称为L1惩罚(L1 penalty)或L1范数(L1
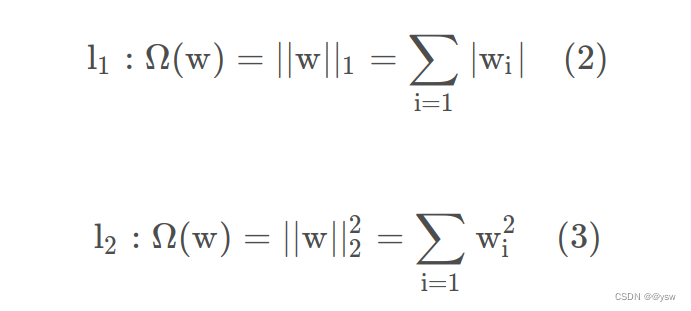
通用扰动攻击是一种更通用的攻击方法,攻击者寻找一种扰动,可以应用于大量输入数据样本,而不是特定的单个样本。攻击者寻找一种扰动,将原始输入数据样本修改为对抗样本,以使模型在对抗样本上产生错误的输出。对抗样本攻击通常专注于欺骗模型的个别数据样本,目标是在特定输入上实现攻击成功。通用扰动攻击(Universal Perturbation Attack)和对抗样本攻击(Adversarial Exampl

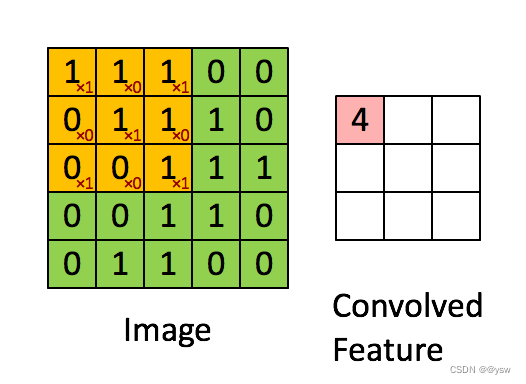
最大池化是对局部的值取最大;平均池化是对局部的值取平均;随机池化是根据概率对局部的值进行采样,采样结果便是池化结果。具体来说,若卷积核是C,输入是X,卷积得到的特征图就是Y,那么CX=Y。反卷积操作就是,Y左乘X转置,c T y = x。反卷积是特殊的卷积,可以将输入还原。分为最大池化,平均池化,随机池化。内积后得到的是特征图。池化的作用就是降维。
当y为0的时候,公式前半部分为0,y' 需要尽可能为0才能使后半部分数值更小;当y为1时,后半部分为0,y'需要尽可能为1才能使前半部分的值更小,这样就达到了让y'尽量靠近y的预期效果。BCELoss:Binary Cross Entropy Loss,二值交叉熵损失,适用于0/1二分类。这要求输出必须在0-1之间,所以为了让网络的输出确保在0-1之间,一般都会加一个Sigmoid。y是真实标签,

它在回归问题中用于特征选择,有助于识别对目标变量有重要影响的特征,同时将不相关的特征的权重收缩为零。L1正则化的效果是使一些权重趋向于零,从而使模型更加稀疏,即某些特征对模型的预测贡献较小,这有助于特征选择和减小模型的复杂度。L1约束(L1 constraint)通常是指在机器学习和优化领域中,对模型的权重(参数)添加L1正则化项,L1正则化项也称为L1惩罚(L1 penalty)或L1范数(L1
深度伪造检测(Deepfake Detection)是指检测和识别深度伪造技术所生成的虚假图像、音频、视频或文本。深度伪造技术使用深度学习和人工智能方法来生成虚假内容,这可能包括合成面部图像、模仿声音、修改视频或生成虚假文本等。深度伪造检测是一个不断发展的领域,研究人员和工程师不断提出新的方法和技术,以提高检测的准确性和鲁棒性。随着深度伪造技术的不断演进,深度伪造检测方法也在不断发展,以适应新的挑
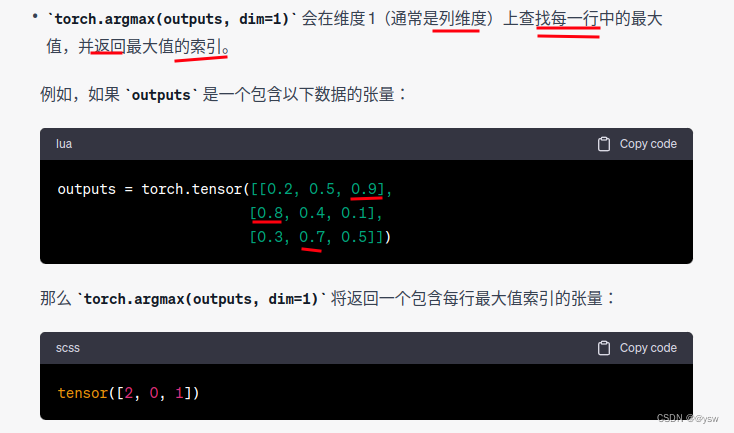
torch.argmax(outputs, dim=1)
单击”View“菜单->“Tool Windows”->"Python Console"即可重新调出。当时不小心将pycharm控制台右键hide了,就是下面这个。
