- @m0_56942491
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LAS:就是 seq2seqCTC:decoder 是 linear classifier 的 seq2seqRNA:输入一个东西就要输出一个东西的 seq2seqRNN-T:输入一个东西可以输出多个东西的 seq2seqNeural Transducer:每次输入一个 window 的 RNN-TMoCha:window 移动伸缩自如的 Neural Transducer。
Text-to-Speech,即文字到语音,也就是我们这个课程所要完成的内容:语音合成。目前的语音合成技术都是端对端训练的。课程大纲会先讲在深度学习流行之前,业界是怎么做的,再讲我们要怎样控制 TTS 来合成出我们想要的声音。Tacotron 用的是一个典型的 Seq2Seq + Attention 的模型架构。它输出还会有个后处理(Post-processing)才会产生声音频谱(spectro
本文主要介绍了语言模型(LM)在语音识别中的重要性和应用。LM能够估计token sequence的概率,包括N-gram、Continuous LM、NN-based LM和RNN-based LM等模型。此外,文章还介绍了如何将LM与语音识别模型(LAS)相结合,包括Shallow Fusion、Deep Fusion和Cold Fusion等融合方式。这些融合方式可以大大提高LAS的预测准确
本文主要介绍了语言模型(LM)在语音识别中的重要性和应用。LM能够估计token sequence的概率,包括N-gram、Continuous LM、NN-based LM和RNN-based LM等模型。此外,文章还介绍了如何将LM与语音识别模型(LAS)相结合,包括Shallow Fusion、Deep Fusion和Cold Fusion等融合方式。这些融合方式可以大大提高LAS的预测准确
我们看下面这张表。在解码部分,LAS 和 RNN-T 会考虑前面的时序对当前时序的影响。而 CTC 并不会考虑之前的时间步已经生成出来的token。所以 LAS 和 RNN-T 在解码部分是相对比较强的。在对齐部分,CTC 和 RNN-T 都是需要考虑对齐的。而因为中间的注意力层,LAS不用显式地考虑对齐,而是采用 soft alignment,使用注意力机制来找出语音和文字之间的关系。在训练部分
一、Text Token二、模型(Speech Recognition)功能三、声音特征 Acoustic Feature四、声音数据集介绍五、常用声音模型介绍(基本上都是 seq2seq 模型)
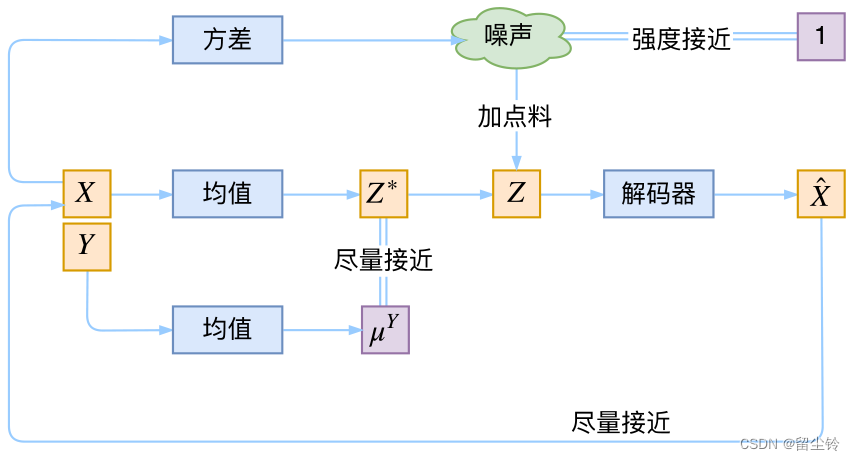
既然是从低维重构原始图像不太行,那如果将隐变量维度取输入维度一样大小呢?似乎还不够,因为标准的 VAE 将后验分布也假设为高斯分布,这限制了模型的表达能力。事实上,人们猜测,由于高斯分布簇只是众多可能的后验分布中极小的一部分,如果后验分布的性质与高斯分布差很远,那么拟合效果就会很糟糕。因此,人们想到了另一个模型:Flow。流模型通过一系列耦合层,可以将复杂的输入分布转化为高斯分布,这样的过程可逆,
本文主要介绍了语言模型(LM)在语音识别中的重要性和应用。LM能够估计token sequence的概率,包括N-gram、Continuous LM、NN-based LM和RNN-based LM等模型。此外,文章还介绍了如何将LM与语音识别模型(LAS)相结合,包括Shallow Fusion、Deep Fusion和Cold Fusion等融合方式。这些融合方式可以大大提高LAS的预测准确
本文主要介绍了语言模型(LM)在语音识别中的重要性和应用。LM能够估计token sequence的概率,包括N-gram、Continuous LM、NN-based LM和RNN-based LM等模型。此外,文章还介绍了如何将LM与语音识别模型(LAS)相结合,包括Shallow Fusion、Deep Fusion和Cold Fusion等融合方式。这些融合方式可以大大提高LAS的预测准确
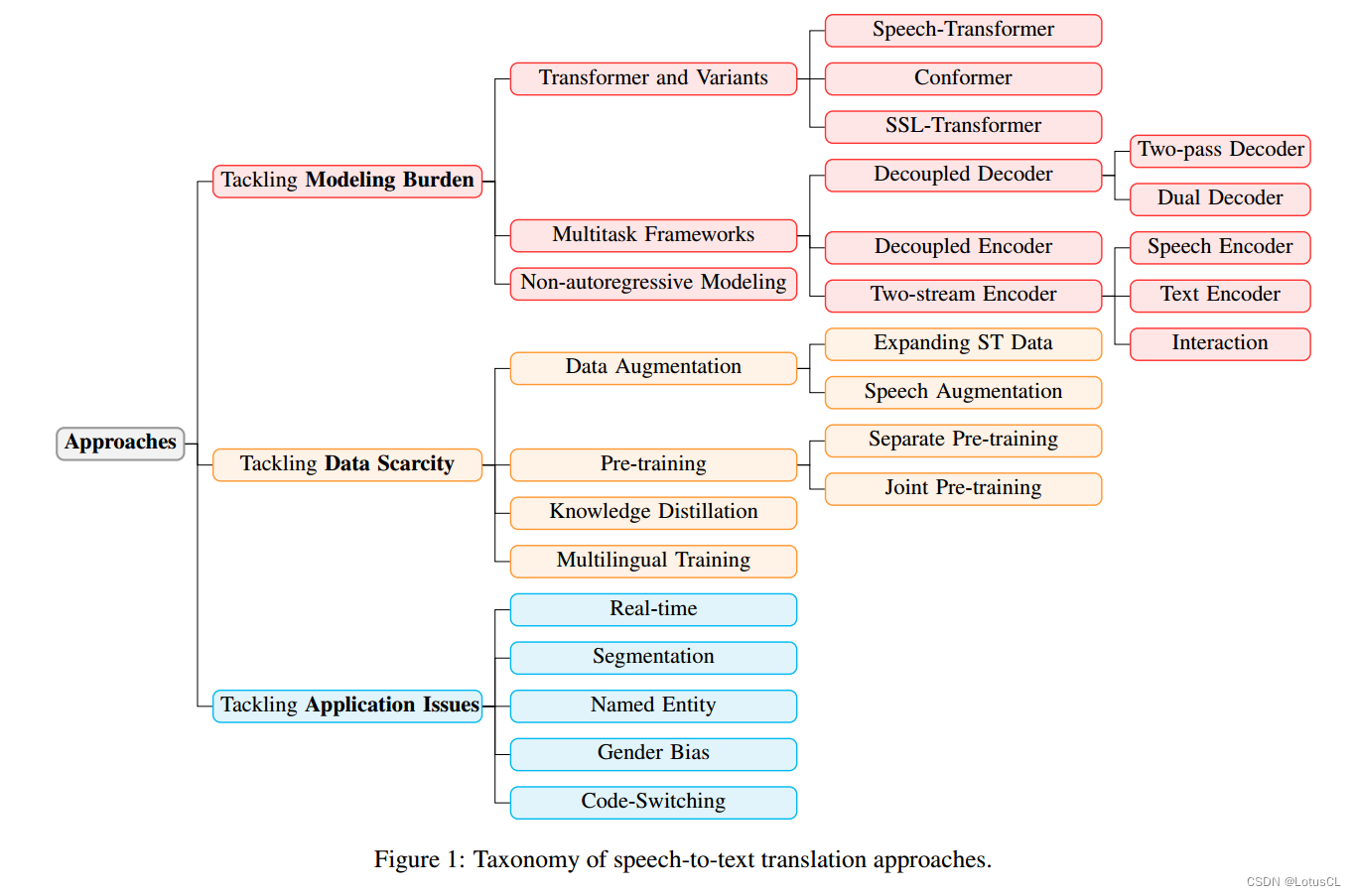
文章探讨了端到端语音翻译(ST)中的挑战和解决方法。针对模型过于沉重的问题,介绍了Transformer模型的变种(Speech-Transformer、Conformer、SSL-Transformer)和多任务框架(解耦解码器、解耦编码器、双流编码器)。针对数据稀缺的问题,提出了数据增强、预训练和知识蒸馏等方法。此外,还探讨了一些应用问题,如实时性、分割、命名实体翻译、码混和以及性别偏见等,最