- @m0_54854484
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
idea安装好以后,是需要简单的配置一下的,而且要分不同的开发环境,此处就不多扩展了,我们就一起来配置java的开发环境准备:1、jdk环境配置 ------- java环境变量请参考(linux环境下java开发环境配置 或 windows环境下java开发环境配置)2、maven build工具(maven项目使用),下载地址3、gradle build工具(gradle项目使用),下载地址4
从传统JQuery转变到Node.js最烦的就是一接手新项目就得npm install,浪费大量时间不说还总会报莫明其妙的错误,这次又遇到了一个error Command failed with exit code 1。因为它的相关处报的问题可能和npm本身有关,我就用yarn install规避,并且也确实能yarn start跑通项目。但就在我想把它打包成dist的时候,yarn build就
2021年4月,华为云联合循环智能发布盘古NLP超大规模预训练语言模型,参数规模达1000亿;联合北京大学发布盘古α超大规模预训练模型,参数规模达2000亿。阿里达摩院发布270亿参数的中文预训练语言模型PLUG,联合清华大学发布参数规模达到1000亿的中文多模态预训练模型M6。2021年6 月,北京智源人工智能研究院发布了超大规模智能模型“悟道 2.0”,参数达到 1.75 万亿,成为当时全球最

盘古NLP大模型由华为云、循环智能和鹏城实验室联合开发,具备领先的语言理解和模型生成能力:在权威的中文语言理解评测基准CLUE榜单中,盘古NLP大模型在总排行榜及分类、阅读理解单项均排名第一,刷新三项榜单世界历史纪录;CV大模型,解决AI工程难以泛化和复制的问题。盘古CV大模型的出现,使AI开发进入工业化模式,即一套流水线能够复制到不同的场景中去,大大节约研发的人力和算力。【问题1】针对不同场景,


盘古NLP大模型由华为云、循环智能和鹏城实验室联合开发,具备领先的语言理解和模型生成能力:在权威的中文语言理解评测基准CLUE榜单中,盘古NLP大模型在总排行榜及分类、阅读理解单项均排名第一,刷新三项榜单世界历史纪录;CV大模型,解决AI工程难以泛化和复制的问题。盘古CV大模型的出现,使AI开发进入工业化模式,即一套流水线能够复制到不同的场景中去,大大节约研发的人力和算力。【问题1】针对不同场景,
😎 作者介绍:资深程序员,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)需要的朋友 点击下方👇👇👇【微信名片】,100%免费领取下面我们一起看看人工智能领域(共144本期刊)中科院分区的升降情
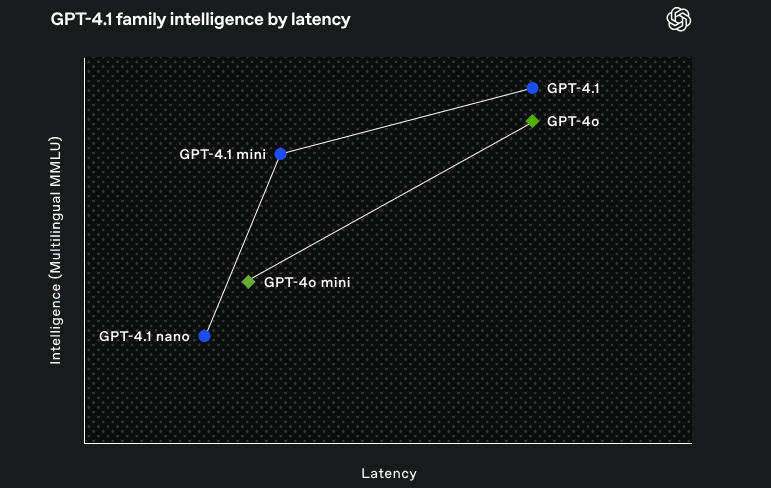
如果你是开发者,现在就能通过 API 调用 GPT-4.1,体验更强大的 AI 能力!知名开发者工具已第一时间集成 GPT-4.1,让编程、调试、文档生成更高效。但 GPT-4.1 API 到底有哪些提升?普通用户什么时候能用上?本文将为你一一揭秘!目前,OpenAI,暂未推出面向普通用户的 ChatGPT 版本。(OpenAI 通常会逐步推广,普通用户可能需要等待后续更新。作为一款 AI 驱动的
开源大模型和闭源大模型各有优缺点,适合不同的应用场景和需求。开源模型在透明性、社区协作和教育资源方面具有优势,而闭源模型则在商业化、控制和支持方面表现更佳。选择哪一种模式取决于具体的应用需求和商业目标。无论哪种模式,推动AI技术的透明和负责任发展,都是未来的关键方向。

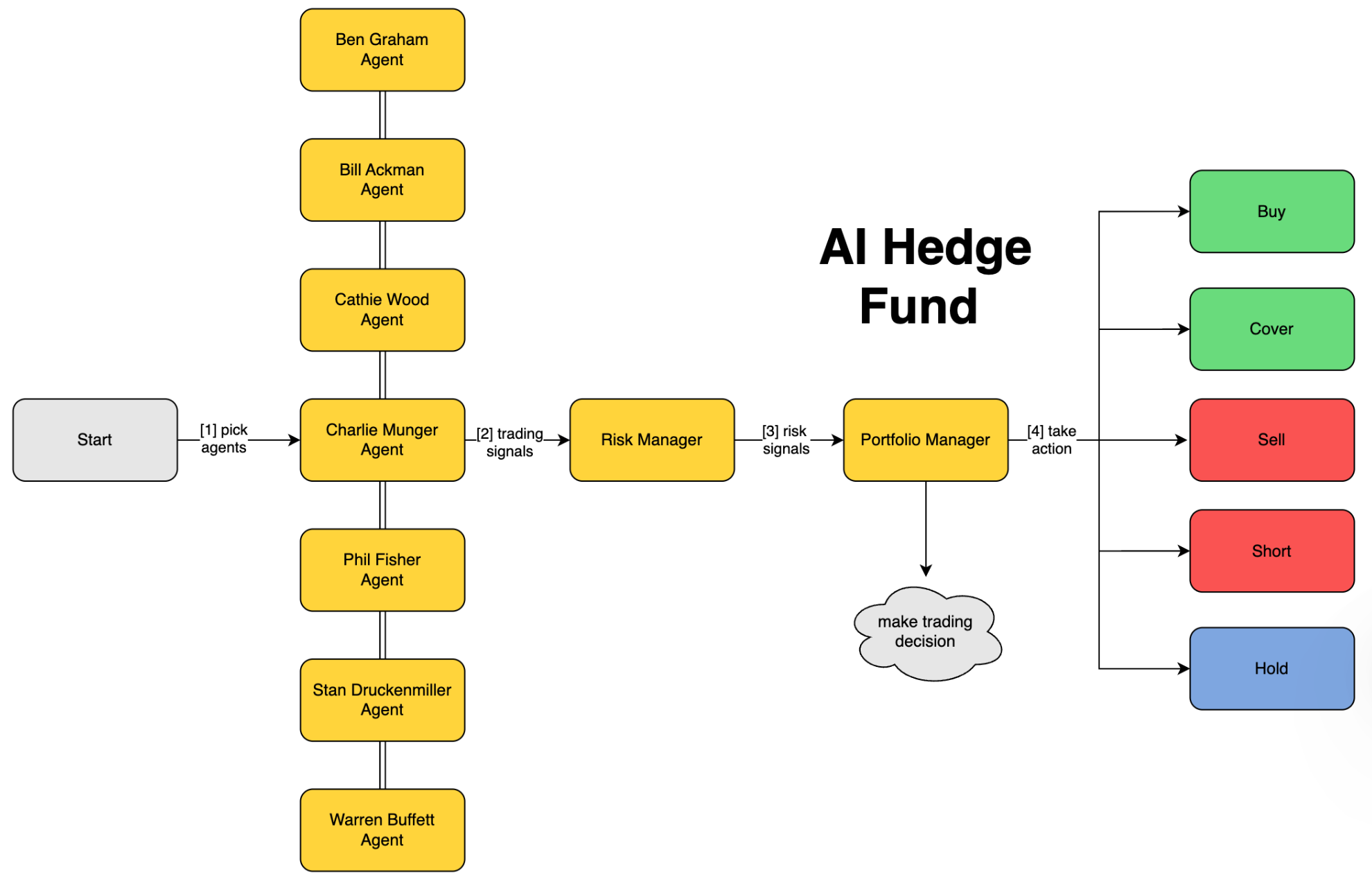
"ai-hedge-fund"是一个概念验证(POC)目,旨在探索使用人工智能进行股票交易决策的可能性。该项目由15个不同的 AI 智能体(Agent)成,这些智能体模拟了著名投资者的思维模式或专注于特定的金融分析领域。项目仅供教育和研究目的,不用于实际交易或投资活动。系统采用了多种大型语言模型(LLM),包括 OpenAI、Groq、Anthropic 和 Deepseek 模型,通过这些 AI