




- @m0_51738372
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
从底层的操作系统、网络,到上层的 Java/C++ 开发,再到最前沿的 DeepSeek、RAG、大模型微调。很多网上的资料还是 2023 年的,但我整理的是 2025-2026 年的最新版本。所以,这段时间我把自己压箱底的宝贝,还有团队内部正在用的学习文档,全部整理出来了。如果链接失效,或者有找不到资料的情况,欢迎在后台给我留言,我会人工帮你处理。这部分是程序员的内功,无论技术怎么变,这些基础永
大模型落地全景图:99个标杆案例揭示产业智能化路径 2024年,中国大模型产业从技术竞赛转向价值落地,99个标杆案例覆盖45个行业,展现出三大核心趋势: 关键技术突破:RAG技术和AI Agent成为主流支撑手段,80%案例采用RAG解决专业知识和数据安全问题; 行业深度赋能:医疗领域实现临床工作流重构(病历生成效率提升67%),金融领域构建千亿参数垂类模型(证券行业NL2API创新); 商业模式

本文提供了Ollama本地大语言模型运行框架的完整使用指南。主要内容包括:1) Ollama在Windows/macOS/Linux系统的安装方法及模型存储路径自定义;2) 推荐使用Chatbox图形界面与本地模型交互;3) 详细介绍了如何手动导入Hugging Face下载的GGUF格式模型,包括创建Modelfile和模型注册流程;4) 常见问题解决方案及推荐模型列表。通过Ollama+Cha

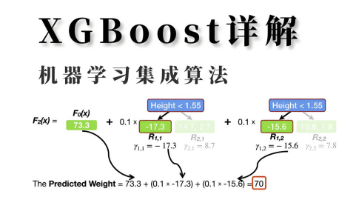
摘要:本文探讨了四种机器学习模型(逻辑回归、决策树、随机森林、XGBoost)在学校足球队员选拔中的应用。逻辑回归适合线性可分数据,决策树直观但易过拟合,随机森林通过多树集成提高稳定性,XGBoost则通过顺序构建优化精度。文章详细比较了这些模型的原理、结构和实现过程,并指出随机森林与XGBoost的关键差异在于训练方式(并行vs顺序)和过拟合控制方法(随机性vs正则化)。模型选择需综合考虑数据特
本文为深度学习面试提供全面指南,涵盖基础理论到实际应用。第一部分讲解神经网络核心概念,包括激活函数和常见网络架构(CNN、RNN、Transformer)。第二部分介绍优化算法(SGD、Adam)和数据处理技巧(数据增强、预处理)。第三部分讨论模型训练与评估,包括过拟合解决方法及评价指标。第四部分对比主流框架TensorFlow和PyTorch。第五部分涉及模型优化方法和部署方案。第六部分详解损失

*石哥,我想转行做 AI,但是不知道从哪里开始学?*石哥,马上要面试了,Redis 和操作系统的高频考点有没有总结?*石哥,大模型现在这么火,有没有适合新手的 RAG 实战项目?说实话,每次看到这些问题,我都很感慨。
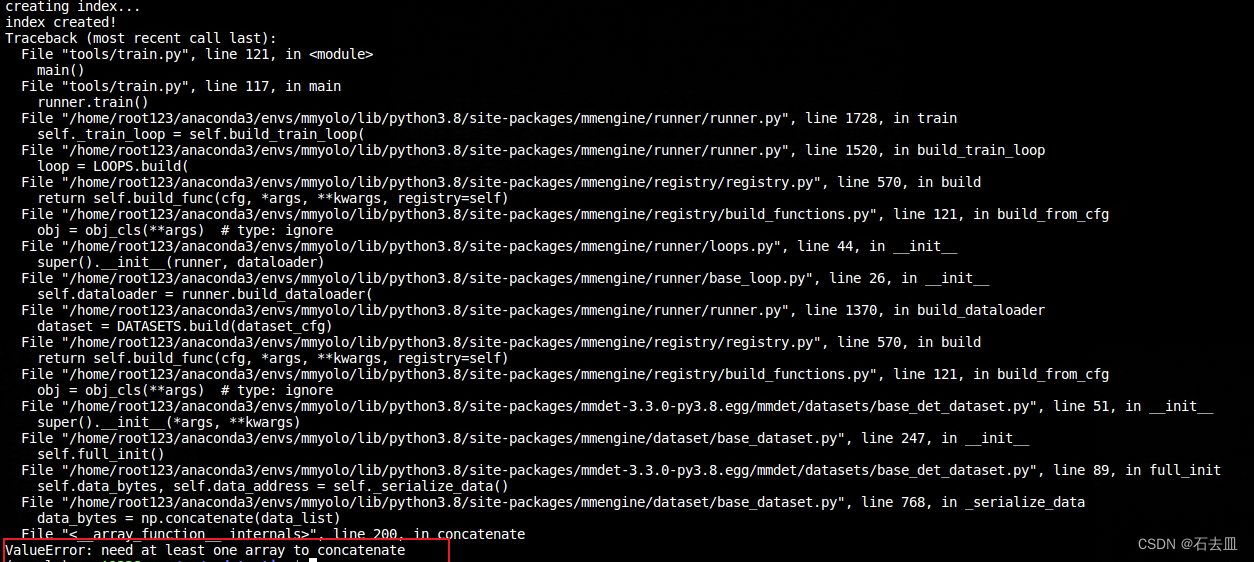
mmdetection在训练自己数据集时候 报错‘ValueError: need at least one array to concatenate’
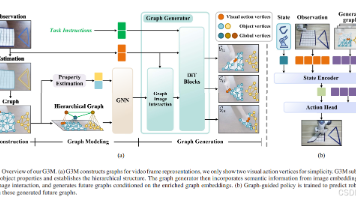
北京理工大学团队在TRO 2026发表论文提出G3M框架,通过图结构生成建模实现视频预训练指导机器人操作。该方法将视频帧转换为包含物体节点和视觉动作节点的图结构,采用分层图建模处理物体属性差异和空间关系,并利用扩散模型生成未来图状态指导策略学习。实验表明,在LIBERO 130任务中仅需20%标注数据即超越现有方法19%以上,跨机器人迁移性能提升35%,验证了图表示对交互本质的有效建模。该工作突破
本文为深度学习面试提供全面指南,涵盖基础理论到实际应用。第一部分讲解神经网络核心概念,包括激活函数和常见网络架构(CNN、RNN、Transformer)。第二部分介绍优化算法(SGD、Adam)和数据处理技巧(数据增强、预处理)。第三部分讨论模型训练与评估,包括过拟合解决方法及评价指标。第四部分对比主流框架TensorFlow和PyTorch。第五部分涉及模型优化方法和部署方案。第六部分详解损失
阿里云盘打不开,闪退,重装也没有用?用默认路径安装即可解决!