- @m0_51517236
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
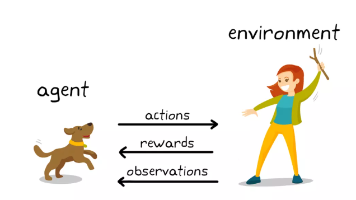
😊你好,我是小航,一个正在变秃、变强的文艺倾年。🔔本文讲解【强化学习】Actor-Critic 演员、评论家,20W字总结(五),期待与你一同探索、学习、进步,一起卷起来叭!🎯想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动
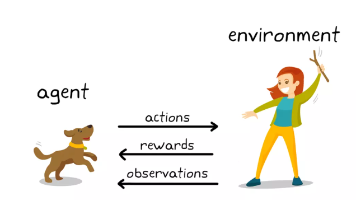
😊你好,我是小航,一个正在变秃、变强的文艺倾年。🔔本文讲解【强化学习】数学推导专题,20W字总结(十五),期待与你一同探索、学习、进步,一起卷起来叭!🎯想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件。一键订阅,长
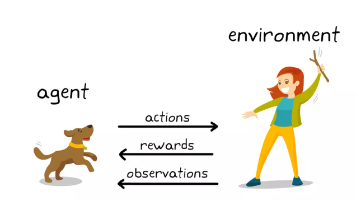
先把"推理"说清楚。这里说的推理,指解答那些需要多步骤、含中间过程的复杂问题——比如数学推导、解谜、复杂编程。“法国首都是哪?”——这是事实问答,不算推理。“一列火车 60 英里/小时开 3 小时走多远?”——这是推理(要先想到"距离 = 速度 × 时间")。所谓推理模型,就是专门优化来处理这类复杂推理任务的 LLM(如 DeepSeek-R1、OpenAI o1)。直接写在回答里(用户能看到),
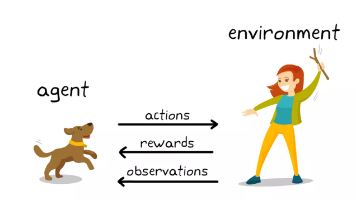
😊你好,我是小航,一个正在变秃、变强的文艺倾年。🔔本文讲解【强化学习】用 GRPO 微调 LLM,20W字总结(十三),期待与你一同探索、学习、进步,一起卷起来叭!🎯想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件
😊你好,我是小航,一个正在变秃、变强的文艺倾年。🔔本文讲解【强化学习】用 GRPO 微调 LLM,20W字总结(十三),期待与你一同探索、学习、进步,一起卷起来叭!🎯想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件
😊你好,我是小航,一个正在变秃、变强的文艺倾年。🔔本文讲解【强化学习】用 GRPO 微调 LLM,20W字总结(十三),期待与你一同探索、学习、进步,一起卷起来叭!🎯想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件
😊你好,我是小航,一个正在变秃、变强的文艺倾年。🔔本文讲解【强化学习】GRPO 与 DeepSeek,20W字总结(十二),期待与你一同探索、学习、进步,一起卷起来叭!🎯想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何
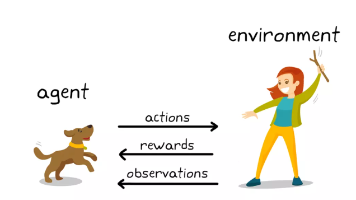
😊你好,我是小航,一个正在变秃、变强的文艺倾年。🔔本文讲解【强化学习】用 DPO 微调 LLM,20W字总结(十一),期待与你一同探索、学习、进步,一起卷起来叭!🎯想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件。
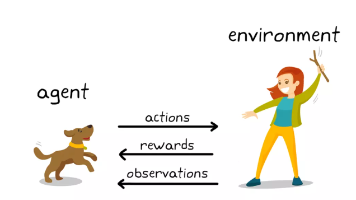
😊你好,我是小航,一个正在变秃、变强的文艺倾年。🔔本文讲解【强化学习】用 PPO 微调 LLM,20W字总结(九),期待与你一同探索、学习、进步,一起卷起来叭!🎯想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件。一
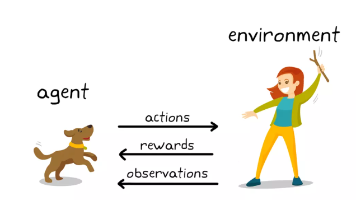
😊你好,我是小航,一个正在变秃、变强的文艺倾年。🔔本文讲解【强化学习】PPO 让智能体稳步提升,20W字总结(六),期待与你一同探索、学习、进步,一起卷起来叭!🎯想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件。一