- @m0_51143578
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
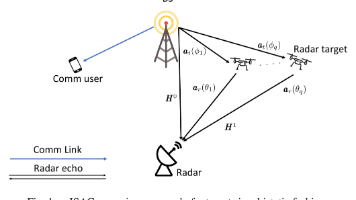
无线系统中的通感一体化(Integrated Sensing and Communication, ISAC)已经成为一种很有前景的范式,它有潜力提升系统性能、提高资源利用效率,并促成雷达感知与无线通信之间的互利交互,从而塑造未来无线技术的发展方向。本文提出两种新方法,用于解决双基地 ISAC 系统中的联合到达角(Angle of Arrival, AoA)和离开角(Angle of Depart
作者:Chang Zhu,Kui Xiong,Yutao Xiang,Zhongyi Wen,Wei Zhang,Huaizong ShaoDOI:10.1109/TSP.2026.3665693多功能相控阵雷达(Multi-Function Phased Array Radar, MFPAR)的感知是现代电子侦察系统的基础。然而,当前对 MFPAR 进行感知与估计的方法主要依赖脉冲描述字(Pul
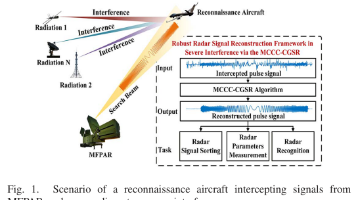
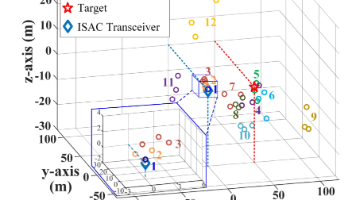
Fig. 8 给出了一个示例,展示了在 CDL-D 模型下,针对单目标场景,使用所提出方案生成的散射簇三维位置,其中每个散射簇包含三个散射体。在确定真实目标峰值时,首先排除距离很小的目标峰,因为这些峰可以确定为由散射簇产生的鬼影目标峰。:在确定 CDL-E 信道模型中散射簇的三维位置后,本文开展雷达感知仿真,以验证多径条件对 ISAC 系统雷达感知性能的影响。对于更加实际的场景,可以采用 Swer
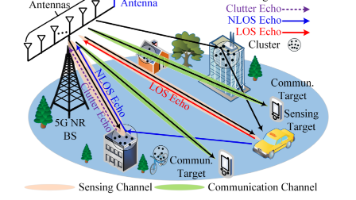
感知通信一体化(Integrated Sensing and Communication, ISAC)技术通过共享频谱与硬件资源,已经被广泛认为是未来第六代(Sixth-Generation, 6G)无线网络中的关键技术。ISAC 信道建模研究支撑着技术演进和系统性能评估。因此,本文面向 6G ISAC 系统,提出一种结合环境散射簇的全新 ISAC 信道模型框架。首先,为考虑感知信道与通信信道之间
由于 WiFi 接入点(Access Point, AP)广泛存在,基于 WiFi 的室内定位受到了广泛关注。基于信号处理的方法能够达到分米级定位精度,但其性能受到 WiFi 系统有限空间分辨率的限制,尤其在强干扰的复杂环境中更为明显。相比之下,基于深度学习的方法即使在复杂环境中也取得了令人印象深刻的性能,但它们往往难以泛化到新环境。本文提出一种用于 WiFi 室内定位的域不变模型学习框架,使模型
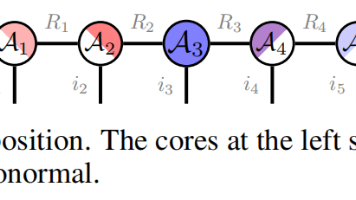
张量列(Tensor Train, TT)分解作为一种高效压缩高维张量数据的流行工具,被广泛应用于机器学习和量子物理领域。在本文中,我们提出了一种高效算法,通过依赖精确杠杆得分采样(exact leverage scores sampling)的交替最小二乘(Alternating Least Squares, ALS)算法来加速计算 TT 分解。
基于第四节中的杂波模型和估计方法,本节重点关注在受杂波污染的 ISAC 测量上运行的接收端杂波抑制。核心要素反映了经典的雷达处理,包括利用多普勒分离的慢时间滤波,利用角度分离的空间波束赋形和置零,以及由干扰协方差估计实现的联合空时自适应滤波。这些操作可以解释为在多普勒、角度和联合域中的线性差分、投影和自适应加权。以下方法假设采用前面介绍的 MIMO-OFDM 波形,但一旦获得合适的空时快拍,它们也
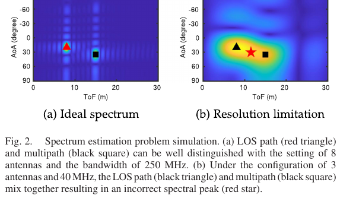
摘要——在毫米波通信中,需要大型天线阵列通过与其他窄波束对准来实现高功率增益,这给在发射(Tx)和接收(Rx)两端高效地在角度域搜索最佳波束方向带来了挑战。由于穷举搜索非常耗时,分层搜索被广泛接受以降低其复杂性,且其性能高度依赖于码本设计。在本文中,我们为分层码本(hierarchical codebook design)设计提出了两个基本准则,并通过联合利用子阵列和去激活(关闭)天线处理技术,设
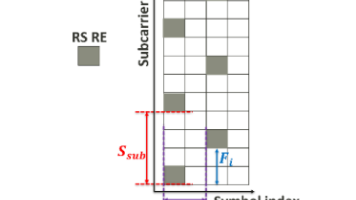
扩展模糊性能 (EAP) 包括所有的栅瓣和旁瓣,它指明了在没有无用峰值的情况下可用于目标参数估计的最大可探测区域,并且对雷达传感器设计至关重要。在双基地感知的 EAP 需求的驱动下,我们提出了针对正交频分复用 (OFDM) 参考信号 (RS) 图样的设计准则。该设计不仅在不同类型的感知算法下改善了时延和多普勒频移域的 EAP,而且还减少了通信感知一体化的资源开销。通过对当前 RS 图样的 FFT
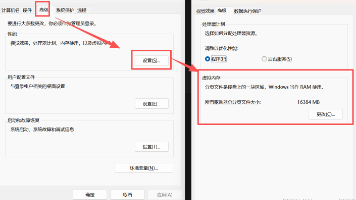
这是最重要的地方,90% 的崩溃原因(比如插件冲突、内存不足、读取某个文件出错)都会记录在这里。(系统已耗尽物理内存(RAM)或虚拟内存(交换空间))java_error 文件中出现了下面的报错提示。(Java 运行环境没有足够的内存来继续运行。