




- @leo0308
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
国内人形机器人行业快速发展,多家新兴企业崭露头角。智元机器人(上海)由华为前高管创立,获高瓴、红杉等投资,估值150亿元,产品远征A1拥有40+自由度。宇树科技(杭州)专注工业应用,其H1机器人扭矩达240Nm。傅里叶智能(上海)依托上海交大,研发康养机器人GR-1。星动纪元(北京)由清华孵化,获5亿元融资,L7机器人速度达3.6m/s。银河通用(北京)与北大合作研发工业机器人Galbot G1。
计算机视觉领域常用数据集总结。

3D目标检测最主要的应用领域是自动驾驶,主流用的传感器是camera和lidar, 一般车上也会配备很多radar, 但是在检测中一般很少用到radar。
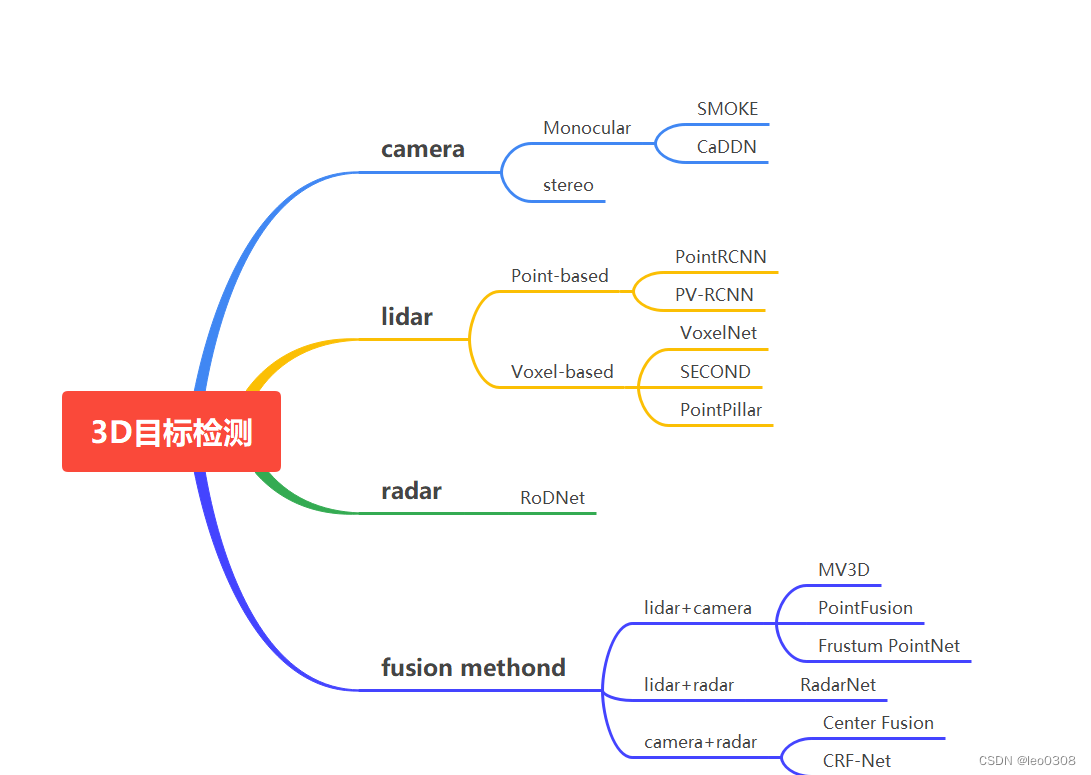
因为模型和权重是开源的, 可以本地部署, 也可以直接使用api调用更为方便。Qwen2.5-VL模型是一个视觉语言多模态大模型。
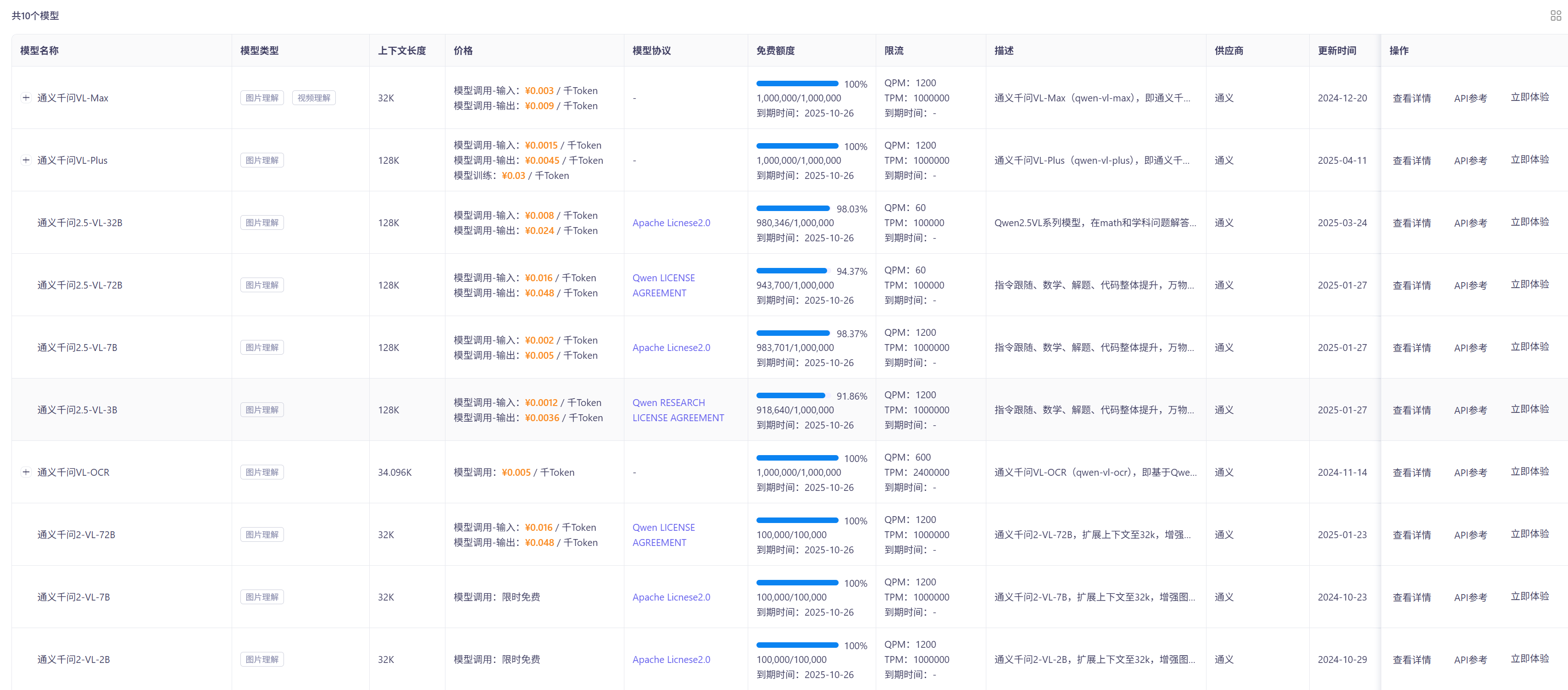
论文: SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation代码: https://github.com/lzccccc/SMOKE0 引言现有的单目3D目标检测基本都是2阶段的, 首先基于2D目标检测生成目标的2D候选区域, 然后针对获取到的2D候选区域预测目标的位置姿态等。 论文认为2D检测是不必要的
人工智能顶级会议与期刊总结
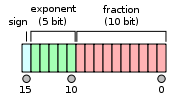
1 float 16与float 321.1 float161.1.1 计算方式float 16又称半精度, 用16个比特也就是2个字节表示一个数。如下图所示, 其中1位符号位, 5位指数位, 10位小数位。那么, 这16个比特位是怎么表示1个数的呢 ? 分3部分:符号位 , 指数部分, 小数部分。a 符号位: 1代表负数, 0代表正数。b 指数部分,5个比特位, 全0和全1有特殊用途,所以是00
labelimg可以用来标注目标检测的数据集, 提供多种格式的输入, 如Pascal Voc, YOLO等。

论文:Categorical Depth Distribution Network for Monocular 3D Object Detection代码:https://github.com/TRAILab/CaDDN0 引言单目3D检测的最大难点在于深度的估计,精确的深度估计是非常困难的, 已有的方法大多估计都不准。 CaDDN 主要的贡献也是在深度估计上, 它的思想是既然精确地深度估计很困难
毫米波雷达-视觉融合感知方法(前融合/特征级融合/数据级融合)