




- @laosao_66
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
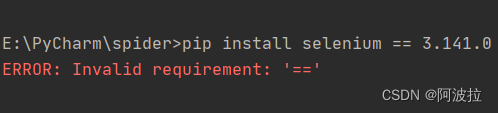
今天安装 selenium包时突然触发这个报错,这个错误通常出现在使用pip安装Python包时,报错的原因是需要注意的是。错误:无效的要求: '=='
字符串集合常用字典树存储,这是一种字符串上的树形数据结构。字典树中每条边都对应一个字,从根节点往下的路径构成一个个字符串。字典树并不直接在节点上存储字符串,而是将词语视作根节点到某节点之间的一条路径,并在终点节点上做个标记"该节点对应词语的结尾".字符串就是一条路径,要查询一个单词,只需顺着这条路径从根节点往下走。如果能走到特殊标记的节点,则说明该字符串在集合中,否则说明不存在。一个典型的字典树如

IV指的是“登录词”(InVocabulary),相应的IV Recall Rate 指的是词典中的词汇被正确召回的概率。连词典中的词汇都无法百分之百召回,说明词典分词的消歧能力不好。就算“商品”“和服”“服务”都在词典中,词典分词依然分不对“商品和服务”。OOV指的是“未登录词”(Out Of Vocabulary),或者俗称的“新词”,也即词典未收录的词汇。如何准确切分00V,乃至识别其语义,

fail表保存的是状态间一对一的关系,存储状态转移失败后应当回退的最佳状态。举个例子:我们的模式串为“自然语言”,如果用字典树查询,以“自“为起点, 找到”自然语言“后,起点又退回到”然“继续扫描...如果扫描到”自然语言“的同时知道”然语言“、”语言“、”言”不在字典树中,则可以少查询三次,观察这三个字符串,它们共享递进式的后缀,所以可以引入后缀树。output 表中的元素有两种,一种是从初始状

完全切分的结果比较没有意义,我们更需要那种有意义的词语序列,而不是所有出现在词典中的单词所构成的链表。具体说来,就是在以某个下标为起点递增查词的过程中,优先输出更长的单词,这种规则被称为最长匹配算法。比较之后发现,双向最长匹配在2、3、5这3种情况下选择出了最好的结果,但在4号句子上选择了错误的结果,使得最终正确率3/6反而小于逆向最长匹配的4/6。第二句话就会产生误差了,我们是需要把“研究”提取

准确率是用来衡量一个系统的准确程度的值,可以理解为一系列评测指标。当预测与答案的数量相等时,准确率指的是系统做出正确判断的次数除以总的测试次数。在中文分词任务中,一般使用在标准数据集上词语级别的精确率、召回率与F1值来衡量分词器的准确程度。这三个术语借用自信息检索与分类问题,常用来衡量搜索引擎和分类器的准确程度。

而这些知识是计算机不拥有的。我们经常省略大量背景知识或常识,比如我们会对朋友说“老地方见” ,而不必指出“ 老地方” 在哪里。对于机构名称,我们经常使用简称,比如“工行” “地税局” ,假定对方熟悉该简称。自然语言中可能存在大量的歧义,而这些歧义在不同的语境下可能表现为不同的意思 ,而机器所处理的编程语言则不能具有任何歧义 ,有一点歧义就会导致代码的运行错误、编译错误。编程语言受到编译器的管理,不

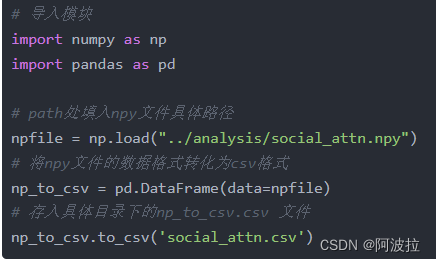
二、 转换为csv文件。一、转换为txt文件。
(1).获取节点内容:适用于标签中嵌套标签的结构 obj.string obj.get_text()【推荐】 (2).节点的属性 tag.name 获取标签名 eg:tag = find('li) print(tag.name) tag.attrs将属性值作为一个字典返回 (3).获取节点属性 obj.attrs.get('title')【常用】 obj.get('title') obj['tit

start、stop、step 分别表示序列的起始值、终止值和步长。start 和 step 是可选参数,如果不指定则默认为 0 和 1。
