




- @kobepaul123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在与 AI 交互中,过长的 prompt 可能带来问题。本文深入剖析当 prompt 超出 token 范围或数量庞大时,AI 面临的困境。提供提高精简度、注意 token 限制及实用实践建议,如明确核心要求、避免冗余信息和分段发送等。让你有效利用 token,提升 AI 工作效率,精准引导 AI 为你服务,不再被过长 prompt 困扰,开启高效的 AI 交互之旅。

QAnything 是网易有道开源的一个问答系统框架,支持私有化部署和SaaS服务两种调用形式。它能够支持多种格式的文件或数据库,提供准确、快速和可靠的问答体验。目前已支持的文件格式包括PDF、Word、PPT、Markdown、Eml、TXT、图片(jpg、png等)以及网页链接等。
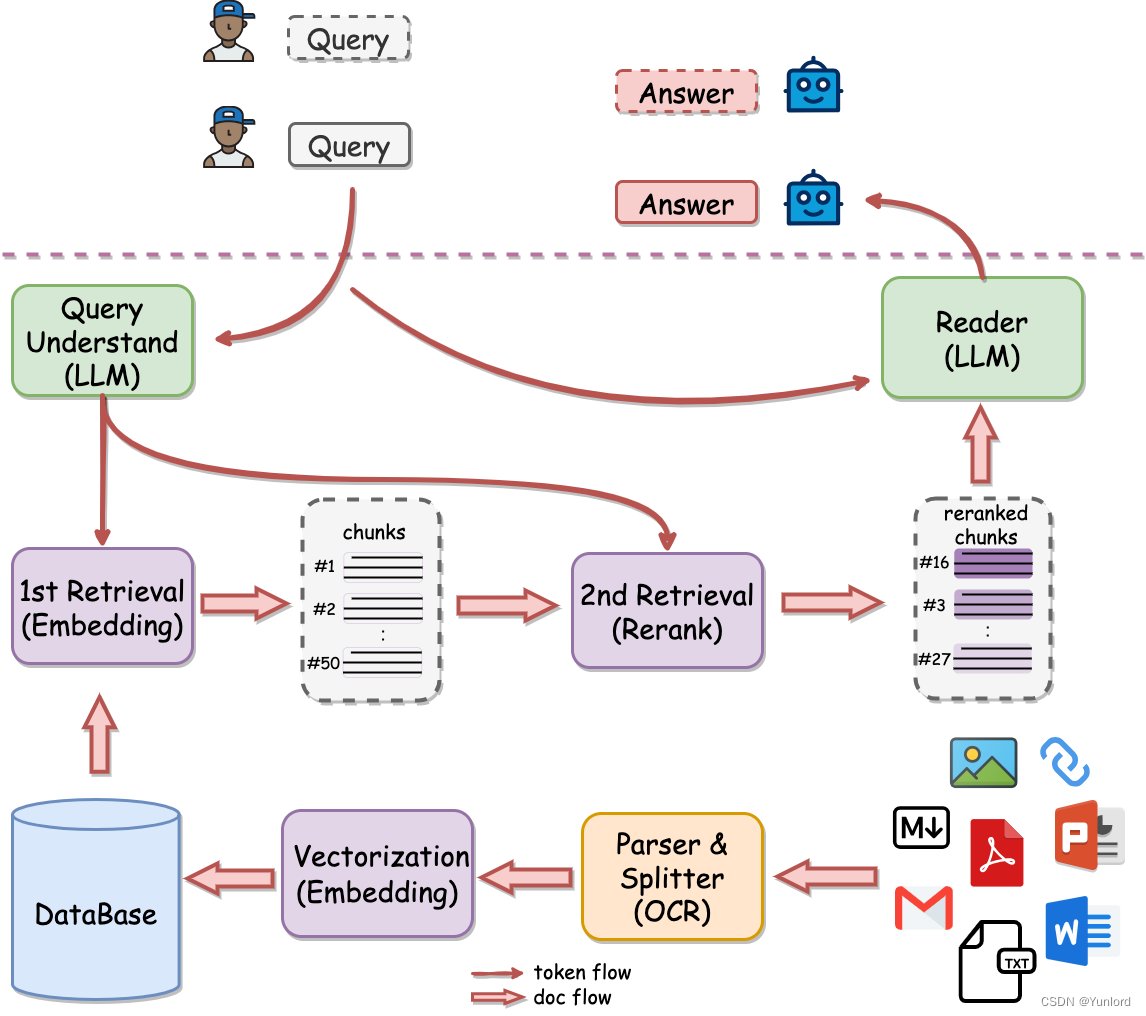
QAnything 是网易有道开源的一个问答系统框架,支持私有化部署和SaaS服务两种调用形式。它能够支持多种格式的文件或数据库,提供准确、快速和可靠的问答体验。目前已支持的文件格式包括PDF、Word、PPT、Markdown、Eml、TXT、图片(jpg、png等)以及网页链接等。
注意力机制与Transformer1 注意力机制介绍PART1 浅谈注意力注意力(attention)是人类学习中必不可少的要素,比如我们去阅读一个文章,或者试着去理解一本书中作者想表达的意思,我们通常在阅读过程中会把注意力放在比较重要的环节上,而不是去把每个细节都会一一记住。人的记忆是有限的,抓重点的学习习惯往往会得到事半功倍的效果。那既然注意力这么重要,我们有没有办法把它用在AI应用中呢? 这

基于yolov5+deepsort+slowfast算法的视频实时行为检测。1. yolov5实现目标检测,确定目标坐标2. deepsort实现目标跟踪,持续标注目标坐标3. slowfast实现动作识别,并给出置信率4. 用框持续框住目标,并将动作类别以及置信度显示在框上

一、小程序代码构成在上一篇文章中,我们通过开发者工具载入模板快速创建了一个QuickStart项目。这个项目里边生成了不同类型的文件:.json后缀的JSON配置文件.wxml后缀的WXML模板文件.wxss后缀的WXSS样式文件.js后缀的JS脚本逻辑文件1.JSON 配置JSON 是一种数据格式,并不是编程语言,在小程序中,JSON扮演的静态配置的角色。可以看到在项目的根目录有一个app.j
目录前言一、 Pytorch介绍1.常见的深度学习框架2.Pytorch框架的崛起3.Pytorch与Tensorflow多方位比较二、Tensors1.Tensor的创建2.Tensor的操作3.Tensor与Numpy三、Autograd的讲解1.模型中的前向传播与反向传播2.利用autograd计算梯度四、 构建神经网络模型1.数据的构造2.模型的构造3.优化器选择和配置4.主函数前言工欲善

前言该实战任务是对豆瓣评分的预测。在这个项目中,我们通过豆瓣评论预测该电影的评分。给定的输入为一段文本,输出为具体的评分。实际上就是一个文本分类任务。在这个项目中,我们需要做:文本的预处理,如停用词的过滤,低频词的过滤,特殊符号的过滤等文本转化成向量,将使用三种方式,分别为tf-idf, word2vec以及BERT向量。训练逻辑回归和朴素贝叶斯模型,并做交叉验证评估模型的准确率一、数据加载1.加

一、docker概述1.什么是dockerDocker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。Docker

朋友们,今天我们要探讨一个备受关注的议题 —— 自ChatGPT发布以来,世界发生了哪些重大变化。从诞生之初的悄然兴起,到如今在全球范围内掀起的惊涛骇浪,ChatGPT的每一步发展都在深刻地重塑着我们的世界,犹如一场惊心动魄的科技盛宴,现在就与大家共同回顾这段波澜壮阔的传奇之旅。这或许是一个能够深刻影响我们未来的真实故事,无论你是 AI 领域的专家,还是之前对 AI 了解不多的小白,这个回顾都能为
