- @knight_9___
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
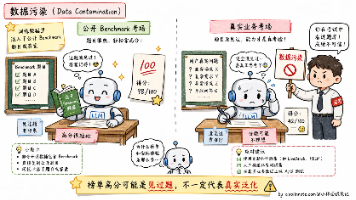
我对这块的理解是,学术 Benchmark 只能作为参考,真正重要的是在自己业务数据上的表现。MMLU / MMLU-Pro 测综合知识,HumanEval / SWE-bench Verified 测代码,GSM8K / MATH / GPQA 测数学和科学推理,LiveBench、Humanity’s Last Exam 这类更新型评测用来缓解数据污染。这些指标看一眼能大概判断模型能力区间,但
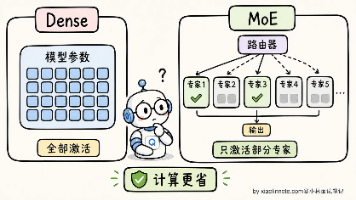
我理解 MoE(Mixture of Experts,混合专家模型)的核心思想是把传统 Transformer 中的 FFN(前馈网络)层替换成 N 个并行的「专家网络」,再加一个 Router 来决定每个 token 进哪个专家。核心设计哲学是「比如 DeepSeek V3 总参数 671B,但每个 token 推理时只激活 37B(约 1/18)。这样能用「总参数 671B 的知识量」+「激活
幻觉不是简单的「模型出错」,而是「生成了流畅合理但实际错误的内容」。元根源是。
我理解量化(Quantization)的本质是把模型参数从「」(FP32 或 FP16)映射到「」(INT8 或 INT4),用更少的比特表示同样的信息。核心收益是显存和速度。一个 7B 模型 FP16 占 14GB,INT4 量化后只剩 4GB,显存压到 1/3.5;同时 INT4 计算比 FP16 快、访存压力也小,推理速度提升 2-4 倍。主流量化方案分两个维度。:FP16 -> INT8

KV Cache 把前面所有 token 的 K 和 V 矩阵缓存在 GPU 显存里,每次新 token 只算自己的 Q、K、V,然后跟缓存的 K/V 做 attention,把总计算量从 O(N³) 降到 O(N²)。如果两个请求的 Prompt 前缀完全相同(比如都用同样的 System Prompt),第一个请求算完的 KV Cache 在 API 服务器上保留下来,第二个请求遇到相同前缀直
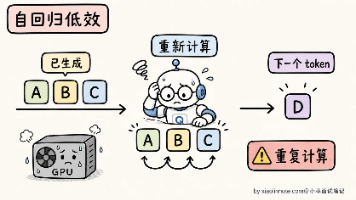
KV Cache 把前面所有 token 的 K 和 V 矩阵缓存在 GPU 显存里,每次新 token 只算自己的 Q、K、V,然后跟缓存的 K/V 做 attention,把总计算量从 O(N³) 降到 O(N²)。如果两个请求的 Prompt 前缀完全相同(比如都用同样的 System Prompt),第一个请求算完的 KV Cache 在 API 服务器上保留下来,第二个请求遇到相同前缀直
这些任务希望模型自然流畅但不能太离谱。Temperature 可以从 0.5~0.7 试起,Top-P 保持 0.9 或官方默认值。这是很多 ChatBot、客服 AI 会尝试的配置区间,平衡了多样性和可控性。不要把某个产品某个版本的默认值当成行业固定标准,模型更新后默认策略也会变。
为什么?因为微调的成本远比想象大。需要准备高质量数据集(光是标注就可能花几万到几十万)、需要 GPU 资源(少说几张 A100)、需要工程经验(调参、防过拟合、防灾难性遗忘)。最坑的是维护成本,底层基础模型一升级(比如 Llama 3 出来要换 Llama 4),你之前微调的版本基本就废了,得重新微调一遍。那什么时候才该上微调?我自己总结的判断标准是这样的。
我理解 Scaling Law(缩放定律)讲的是大模型的损失值如何随模型规模、训练数据量、训练算力这三个量变化的可预测关系。OpenAI 在 2020 年提出,DeepMind 在 2022 年的 Chinchilla 论文里精修。核心发现是三个。第一,损失值随这三个量按幂律下降(loss ∝ N^-α,N 是规模)。意思是规模翻倍,损失值按可预测的比例下降,没有「饱和点」。第二,参数和数据要按一
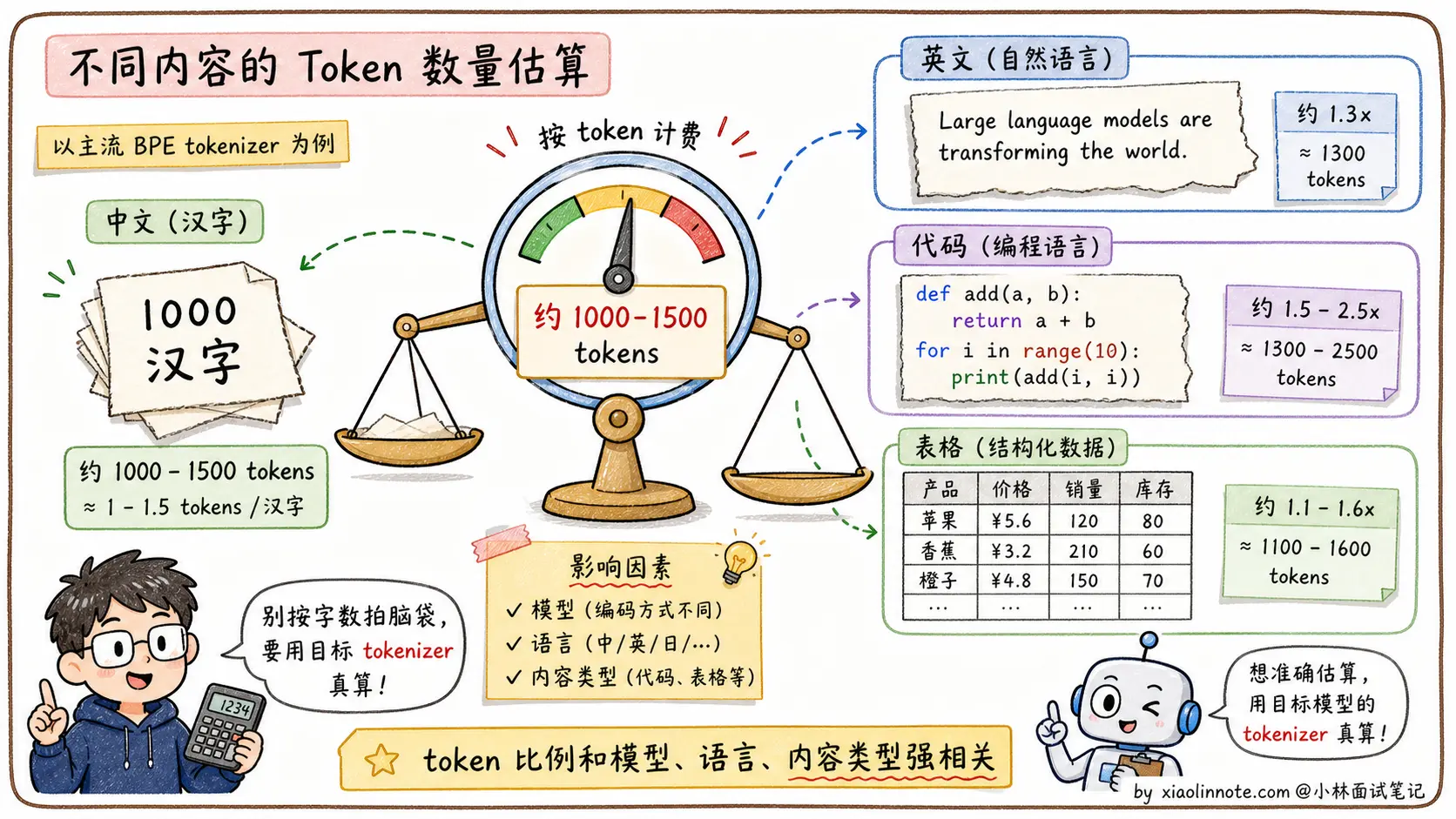
我觉得面试被问到 Tokenizer,最重要的是先说清楚「为什么需要它」,模型只能处理整数,不认识字符串,Tokenizer 就是把文字转成数字 ID 序列的桥梁。至于原理,主流路线都是子词分词,常见实现有 BPE、SentencePiece / Unigram、WordPiece 等。BPE 的直觉是从小单元出发,反复把出现频率最高的相邻片段合并成新 token,最终形成一个几万到十几万规模的词