




- @hzp666
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这是一个java写的获取百度网盘真实下载链接进行下载的程序。 程序里面一些参数拼接是根据浏览器抓包来的。具体的抓包方法网上一大堆,可以参考。这里给出了源码和导出的jar包。 url网址使用于百度分享的地址。暂时没有适配有提取码的地址。运行的方法: 1、在当前的目录打开cmd,默认不带参数就是用默认的测试的url。 java -jar BaiduPanURL.jar2、如果想使用自己...
摘要:Spark SQL的spark.sql.sources.partitionOverwriteMode参数控制分区覆盖行为:static模式会清空全表只保留本次写入分区,而dynamic模式仅覆盖匹配分区。Hive动态分区插入时,Spark 2.3+版本默认使用static模式会导致所有分区被意外覆盖。需将该参数改为dynamic并配合hive.exec.dynamic.partition参数
Abracadabra(魔曰)是一款开源、安全、高效的文本加密工具,能将数据转换为由汉字构成的文言文格式。该工具完全开源,部署和使用简单便捷。项目源码托管于GitHub(SheepChef/Abracadabra),同时提供CSDN下载渠道(编号91834443)。这种创新的加密方式既保证了数据安全,又赋予加密文本独特的古文风格。
到此,我们就成功解决vscode无法获取git上最新的远程分支的问题了。1)从代码托管平台上的分支截图可以看出有个。发现根本没有该分支,因此也无法切换。我们发现已经能查看到了。
总体步骤:安装git工具,生成ssh秘钥,配置gitlab秘钥,配置sourceTree.1.安装git省略2.git生成ssh秘钥3.配置sourceTree。

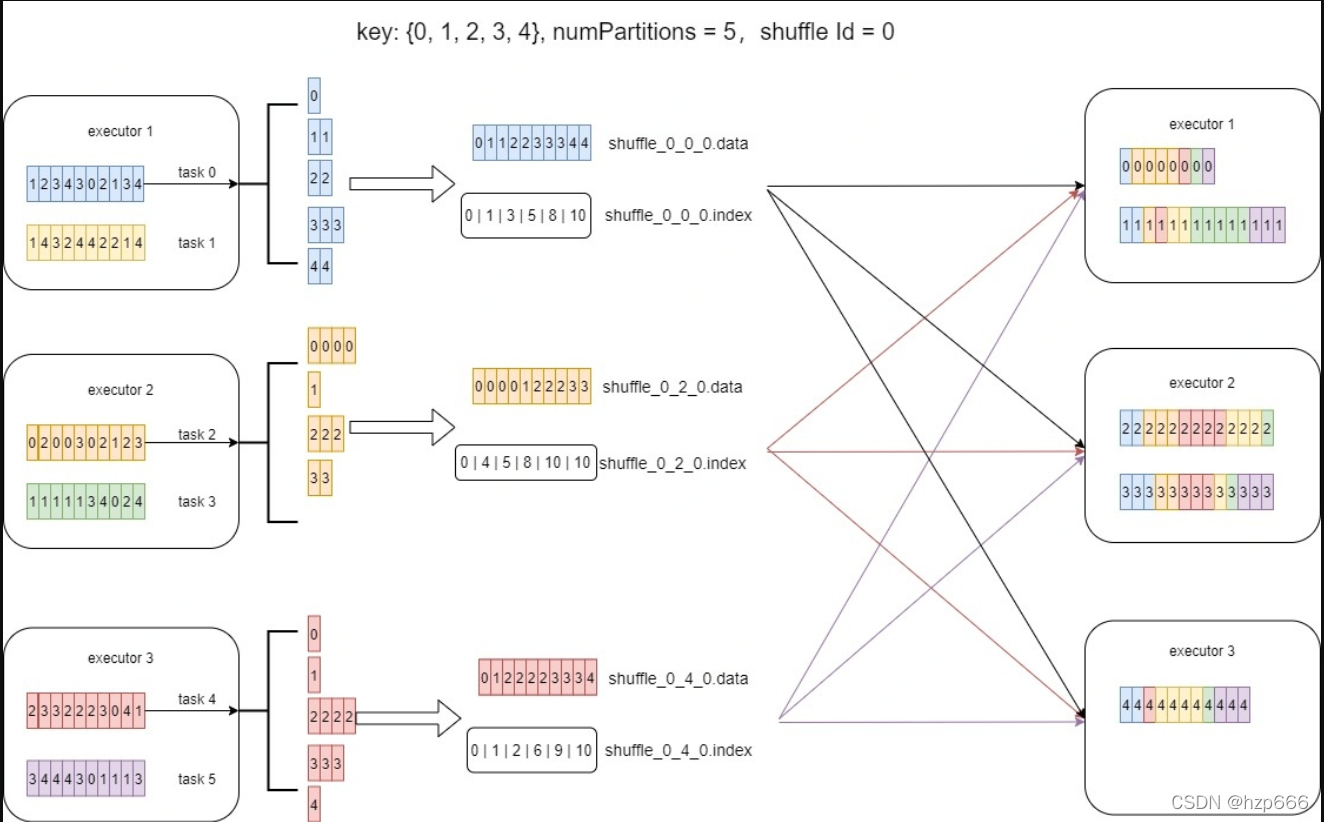
一、Spark Shuffle对于 spark shuffle 这一过程,网络上有非常多的文章进行说明,这里简单描述介绍下。Spark 包含三种 shuffle writer,上图展示的是 BypassMergeSortShuffleWriter (有兴趣的用户可以自行阅读社区源码),以此为例简单介绍 spark shuffle。Shuffle Writer 会将每个 shuffle write
vscode 中添加 SQL Formatter,格式化sql1.打开vscode 的扩展模块2.搜索 SQL Formatter, 点击安装3.打开需要格式化的代码(在VSCODE中,新建一个文件 ctrl + N , 会让选择 编程语言, 选sql)现在你就可以使用alt+shift+f组合键来快速格式化你在VS Code中的代码了。格式化后的代码...
异常信息:Job aborted due to stage failure: Total size of serialized results of 17509 tasks (2.0 GiB) is bigger thanspark.driver.maxResultSize (2.0 GiB)解决方案:spark.driver.maxResultSize默认大小为1G,指的是每个Spark act
1.RDD设计背景为了解决 MapReduce的 频繁磁盘IO开销,序列化和反序列化的开销,因为从磁盘读取数据转换为对象 需要反序列化, 在对象落磁盘时候 需要序列化
绝大多数互联网公司没时间建模、治理,直接拖宽表。业务变更频繁、建模缺位、指标爆炸,是导致互联网大数据环境中数据质量的低下的根本原因。而在部委、集团中,时间相对充裕一些,标准更规范一些,但是同样面临部委和省级之间、各系统之间数据交换、对齐的问题。因此,在不同的环境中,数据治理的重点和偏向都是完全不一样的。今天分享的内容从实战出发,到落地结束。数据治理最难的不是系统建设,而是落地困难。所以今天先跟大家