




- @huayidw
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1. GPIO 按键、简单 UART:→ 传统中断 + Tasklet2. I2C/SPI 传感器:→ 线程化中断 (request_threaded_irq)3. 网卡、块设备:→ 传统中断 + NAPI/Softirq4. 复杂后台任务:→ 工作队列 或 内核线程5. 实时性要求高:→ 传统中断 + 高优先级内核线程中断上半部:快速、不睡眠、禁止中断中断下半部:延迟、可睡眠(work queu
* 简要示例:将 DMA RX 缓冲封装为自定义 pbuf(释放时归还 DMA 缓冲) *//* 归还 rx->dma 给 RX 环,并置 OWN 给 DMA *//* ... */pbuf_alloced_custom(PBUF_RAW, rx->len, PBUF_POOL /*标记用途*/, &pc,/* 上送栈:netif->input(&pc.pbuf, netif);*/payload

序列(raw API):udp_send / udp_sendto → udp_sendto_if_src → 构造 UDP 头(pbuf_add_header)→ 校验/设置 udphdr → ip_output_if_src/ip_output_if → netif->linkoutput(low_level_output)全局头:udp_pcbs(链表头)。序列:ethernet_input
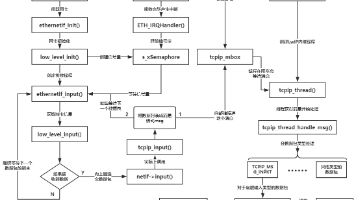
本文系统分析了lwIP网络协议栈的数据接收处理流程,重点阐述了从网卡驱动到协议栈核心线程tcpip_thread的完整数据路径。文章详细说明了硬件中断处理、驱动层接收线程、tcpip_thread消息处理等关键环节的交互机制,包括pbuf内存管理约定、线程间通信方式(邮箱投递)和不同锁策略的配置影响。同时提供了驱动实现建议、常见问题排查方法和系统参数调优指导,涵盖了零拷贝、缓存一致性、消息队列深度
FSMC、QSPI和OSPI代表了嵌入式系统外部存储接口的发展历程:从并行到串行,从单线到多线。在内存映射和XIP方面,三种接口都支持,但实现复杂度和性能各不相同。对于现代STM32应用,QSPI和OSPI因其更好的性能/空间比和灵活性而成为更流行的选择,特别是对于需要执行复杂代码的应用程序。
中国商用密码算法体系│ 国密算法族 ││ ││ │ 核心算法 │ ││ │ │ 椭圆曲线 │ 哈希算法 │ 分组密码 │ │ ││ │ │ 公钥算法 │ (摘要算法) │ (对称加密) │ │ ││ │ ││ │ 扩展算法 │ ││ │ │ SM9 │ ZUC │ 其他算法 │ │ ││ │ │ 标识密码 │ 序列密码 │ (SM1/SCB2) │ │ ││ │ │ (IBE算法) │ (流密码)
堆和栈是计算机内存管理中两个最重要的概念,它们在程序执行过程中承担着不同的职责,有着截然不同的特性和使用场景。2. 栈(Stack)详解2.1 栈的工作原理2.2 栈的使用示例2.3 栈帧结构详解2.4 栈溢出问题3. 堆(Heap)详解3.1 堆的工作原理3.2 堆的使用示例3.3 堆内存管理器原理3.4 堆内存问题与解决方案4. 内存布局全局视图4.1 程序内存布局4.2 不同存储区域的变量示
在现代高性能单片机(如ARM Cortex-M7、Cortex-A系列在MCU中的应用)中,Memory Protection Unit (MPU) 和Cache系统的协同工作对系统性能有着决定性影响。本文将深入分析MPU配置如何影响Cache命中率,多主设备对RAM访问的竞争问题,以及Cache一致性维护策略。分层优化: 根据访问频率和模式配置不同的Cache策略一致性权衡: 在性能和一致性之间
Flash存储(包括NOR Flash和NAND Flash)由于擦写次数有限,确实需要进行均匀磨损(Wear Leveling)管理。在实际嵌入式系统中,对于大容量存储(NAND Flash、SD卡)几乎总是需要均匀磨损策略;而对于小容量存储(如启动NOR Flash),可通过合理应用设计(减少写操作,数据分区)来延长寿命。在实际嵌入式系统设计中,通常会根据应用需求结合使用多种存储技术,以平衡性
使用开漏输出模式配置GPIO实现起始、停止、发送、接收、应答等基本信号操作按照协议时序编写读写函数注意时钟速率控制和时序延迟。
