- @helloaiti
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
定性分析中,其能识别关键异常,但存在过度泛化和幻觉现象见下图3。:基于MLP - Mixer设计双流式投影器,融合低层次空间细节和高层次抽象语义特征,通过两个平行的 MLP - Mixer 模块分别处理不同层的图像特征,然后与文本嵌入融合,比简单线性投影更能捕捉丰富的跨模态交互,提高LLM解码准确性。:采用 DCFormer,将3D卷积分解为三个平行的1D 卷积,降低计算复杂度,有效捕捉3D图像的
基于Patch的高分辨率深度估计方法虽能缓解内存问题,但在重新组装估计的深度Patch时会引入深度不连续问题,即边界伪影,且为解决该问题采用的测试时集成平均方法会降低推理速度,在实际应用中存在局限性。:零样本深度估计模型在大规模数据集上训练,泛化性强,但训练数据分辨率低,处理高分辨率图像时,直接处理会导致内存消耗大且精度下降,下采样则会丢失边缘细节,影响深度估计的准确性,使整体结构出现低频伪影。在
在 Visdrone、UAVDT 和 AI-TOD 数据集上的实验结果表明,FBRT-YOLO 在不同模型规模下均优于现有实时检测器,实现了精度与效率的良好平衡,为航拍图像实时检测提供了更有效的解决方案。轻量化设计:精简冗余计算,相比YOLOv8系列,参数量减少最高74%,推理速度提升显著。AI-TOD 数据集实验结果:该数据集包含大量小目标,FBRT-YOLO相比基线模型,参数数量减少74%,G
提出将身体和手部作为两个互补数据模态的跨模态架构,身体流提取全局身体动态(如走路、跳跃),手部流专注于手指关节的细粒度运动(如捏、握),以跨模态方式整合详细的手部姿态信息和全身姿态,使模型能同时捕捉全局身体动态和精细的手部关节运动。2.特征模糊:统一图表示(如SkeleT)整合全身、手部和足部关键点时,但由于身体和手部动作特征差异以及空间池化时细微特征的丢失,导致手部细节模糊,限制精确识别手部动作

在产业方面,我国人工智能产业规模不断扩大,体系更加全面,相关企业超4500家,核心产业规模接近6000亿元。在融资方面,生成式人工智能备受青睐,OpenAI估值大幅增长,我国政府引导基金、民间资本和大型企业纷纷投入资金,推动行业发展。我们需要各方共同努力,突破技术瓶颈,规范行业发展,让这一技术更好地服务社会,创造美好的未来。多模态大模型的出现,拓展了生成式人工智能的应用场景。【生成式人工智能发展历

经ViT处理后,通过特定计算得到聚焦于目标对象的特征,再利用基于CenterNet架构的边界框头输出跟踪结果,并将特征映射到2D特征图,为后续多视图集成做准备。和其他多视图数据集相比,它提供了更丰富的对象类别(27类,远超其他数据集的1 - 8类)和更多的视频(260 个),且采用实用的3 - 4视图相机设置,是唯一结合多视图跟踪、丰富对象类别、缺失标签注释和校准信息的数据集。跟踪的时候呢,当目标
在 Visdrone、UAVDT 和 AI-TOD 数据集上的实验结果表明,FBRT-YOLO 在不同模型规模下均优于现有实时检测器,实现了精度与效率的良好平衡,为航拍图像实时检测提供了更有效的解决方案。轻量化设计:精简冗余计算,相比YOLOv8系列,参数量减少最高74%,推理速度提升显著。AI-TOD 数据集实验结果:该数据集包含大量小目标,FBRT-YOLO相比基线模型,参数数量减少74%,G
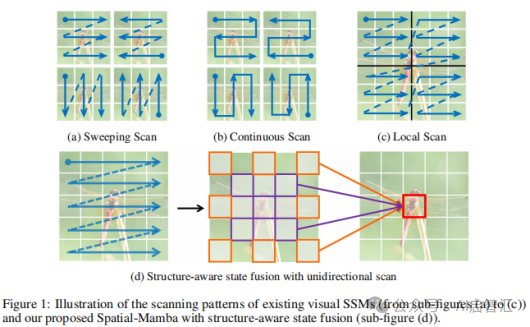
Spatial-Mamba-T的Top-1准确率达到83.5%,超过ConvNeXt-T 1.4%,超越Swin-T 2.2%、NAT-T 0.3%,比VMamba-T和 LocalVMamba-T分别高出1.0%和0.8%。Spatial-Mamba-S和Spatial-Mamba-B的Top-1准确率分别为84.6%和85.3%,优于NAT-S、NAT-B、VMamba-S和VMamba-B。
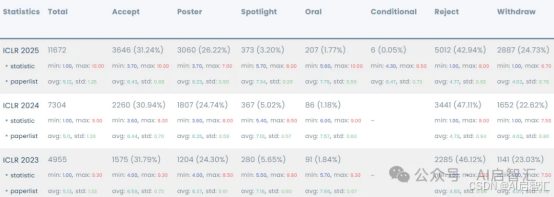
从三年标题词云结果可以看出,三年来,reinforcement_learning始终保持器热门的位置,24和25年large_language_models、diffusion_models出现次数开始领先reinforcement_learning,这也是这两年最火的两个方向。论文发表量前五机构Google、tsinghua_university、zhejiang_university、mass
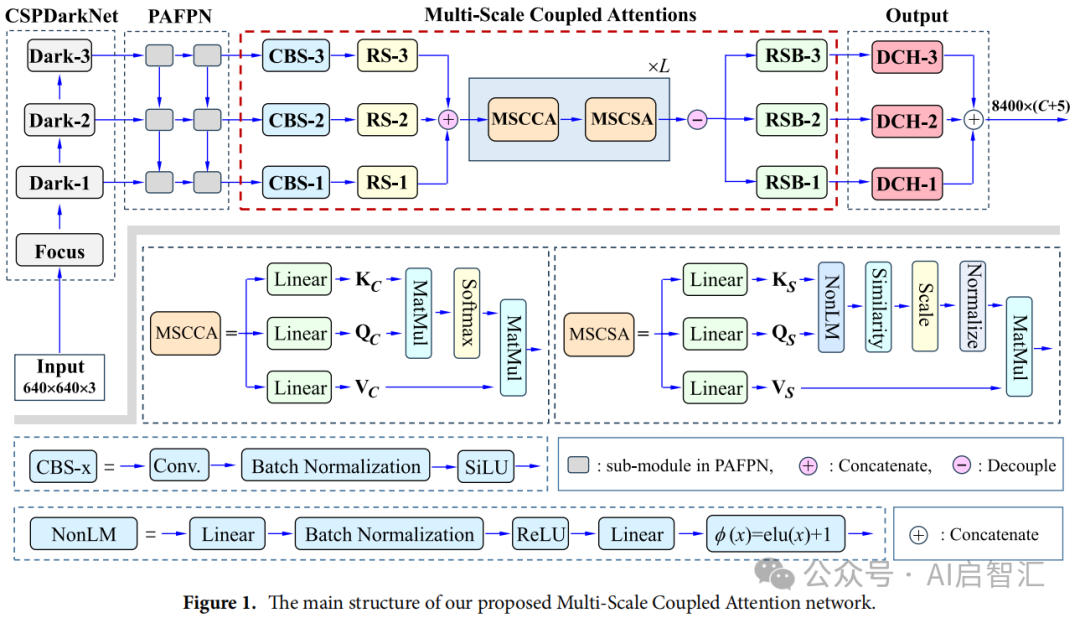
头部将第2、3、4阶段的输出(P2、P3和P4)通过1x1 卷积和标准上采样操作匹配空间和通道大小后,采用加法融合,然后经过几个 MBConv 块和输出层进行预测和上采样。:由通道注意力和空间注意力模块组成。编码器基于MobileNet,去除全连接层,使用多尺度卷积核(1×1、3×3和5×5)替代原有的3×3卷积核,扩大卷积感受野,增强特征提取能力;CSPDarkNet 生成多尺度特征图,PAFP