- @hai40587
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
TensorFlow的核心是一个计算图(Graph),图中的节点(Nodes)代表数学操作,而边(Edges)则代表在这些节点之间流动的多维数组(Tensors)。这种设计使得TensorFlow能够高效地执行大规模数值计算,特别是在GPU和TPU等硬件上。TensorFlow支持多种编程范式,包括静态图(Eager Execution之前的模式)和动态图(Eager Execution)。静态图

AI绘画,简而言之,是指利用人工智能技术辅助或完全自动生成艺术作品的过程。这一过程可能涉及机器学习、深度学习、计算机视觉、自然语言处理等多种技术,使得计算机能够模仿甚至超越人类的创作能力,创作出具有独特风格和情感的画作。

本文介绍了一个基于Flask和Vue的电商管理系统。系统采用前后端分离架构,后端使用Python的Flask框架,前端采用Vue框架,数据库使用MySQL。文章详细阐述了系统架构设计和管理员功能模块的实现过程,包括首页管理、个人中心、用户管理、广告管理、商品管理、订单管理等。管理员通过Vue前端发送请求到Flask后端接口,后端处理数据请求并与数据库交互,前端动态渲染数据。系统实现了电商平台的核心
同时,随着机器学习和深度学习技术的不断发展,MATLAB在图像处理领域的应用也将更加深入和广泛。MATLAB,作为美国MathWorks公司出品的商业数学软件,以其强大的矩阵运算能力和丰富的函数库,在图像处理领域得到了广泛的应用。MATLAB不仅提供了基础的图像处理功能,还通过图像处理工具箱(Image Processing Toolbox)等高级工具,为用户提供了从图像读取、显示、转换到高级分析

本文介绍了基于Python和OpenCV的疲劳检测系统设计与实现。系统采用MySQL数据库存储用户信息和检测数据,通过E-R图展示了照片信息的数据结构。系统功能包括:1)登录验证界面;2)首页统计仪表盘;3)图片识别模块,支持摄像头拍照和图片上传进行疲劳检测;4)照片分析模块,通过图表展示眼睛状态、哈欠频率等数据;5)照片管理功能,记录检测结果并支持查询删除;6)用户管理界面,实现密码修改和用户新
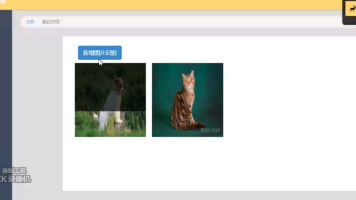
本文介绍了基于Python+Django+MySQL开发的AI动物识别系统,采用B/S架构和OpenCV技术,通过卷积神经网络构建动物识别模型。系统包含登录验证、图片识别、管理和分析四大功能模块:登录模块保障数据安全;识别模块可自动识别上传图片中的动物种类;管理模块支持图片信息查看与删除;分析模块通过可视化图表统计识别数据。该系统可为动物保护、生态研究等领域提供专业服务,同时便于管理员掌握模型训练
本文介绍了基于改进高斯混合模型的图割算法系统,采用Python、MySQL和B/S架构开发。系统包含管理员登录、后台管理、图片上传和图像分割功能模块,界面设计简洁高效。通过单元测试和集成测试验证了系统各功能的可靠性,包括信息增删改查等操作均运行正常。该系统适用于图像处理领域,为开发者提供了完整的算法实现方案和技术支持。
本文介绍了基于改进高斯混合模型的图割算法系统设计与实现。系统采用Python和MySQL技术,包含管理员登录、后台管理、图片上传和图像分割等功能模块。管理员通过权限验证登录后台,可进行图片上传操作;系统对上传图片运用改进的高斯混合模型算法进行图像分割处理,并展示分割结果。该系统为图像处理领域提供了一种有效的解决方案,适用于毕业设计及作业项目开发需求。文章末尾提供源码获取方式,并欢迎咨询毕设选题和技
本文介绍了基于Python的计算机视觉答题卡识别系统设计与实现。系统采用Django框架开发,结合OpenCV图像处理技术和MySQL数据库,实现了答题卡识别、管理、分析等功能模块。系统包含用户登录(含拼图验证)、首页统计、题卡识别上传、题卡管理删除、得分分析可视化以及用户管理等界面。通过功能测试验证了系统各模块的有效性,能够满足答题卡自动识别评分需求。该系统为教育领域提供了一种高效便捷的答题卡处

💟博主:程序员陈辰:CSDN作者、博客专家、全栈领域优质创作者💟专注于计算机毕业设计,大数据、深度学习、Java、小程序、python、安卓等技术领域📲文章末尾获取源码+数据库🌈还有大家在毕设选题(免费咨询指导选题),毕设、作业项目以及论文编写等相关问题⭐都可以直接找我解答、希望可以帮助更多人。