




- @guse1125
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:当前大模型开源框架正推动AI技术民主化,主流框架各具特色:vLLM通过PagedAttention实现高效推理,DeepSeek系列在推理任务上媲美GPT-5,MiMo-V2-Flash采用MoE架构平衡效率与性能,OpenClaw构建AI Agent生态。这些框架通过降低技术门槛、促进全球协作,加速AI创新。未来趋势包括多模态融合、绿色算力优化以及人机协作新范式,开源生态正推动AI从&qu

本文是一篇关于人工智能(AI)学习的入门指南,旨在为对AI感兴趣的读者提供学习路径和实践建议。文章首先介绍了AI的基本概念及其在医疗、金融、交通和教育等领域的应用。接着,详细阐述了学习AI所需的数学基础(如线性代数、概率论和微积分)、编程语言(如Python和R)以及开发环境的搭建。随后,通过两个入门项目(鸢尾花分类和手写数字识别)引导读者进行实践操作。最后,文章建议读者通过在线课程、开源项目、技

2026年Java技术生态呈现"云原生+AI工程化"双轮驱动格局。云原生领域,SpringBoot 3.x和Quarkus等框架通过GraalVM实现快速启动和低内存占用;AI集成方面,LangChain4J成为大模型开发标准。技术选型需结合业务场景:传统企业推荐SpringBoot,云原生项目适合Quarkus,AI工程化首选LangChain4J。未来趋势包括原生编译普及、

人工智能应用面临多重挑战:认知偏差导致落地断层,如生成式AI的虚构信息问题;数据质量危机带来算法偏见,在招聘、医疗等领域存在歧视;模型"黑箱"特性影响可解释性和信任度;安全隐私问题突出,需加强防护;算力需求激增带来可持续性压力;数字鸿沟加剧教育不平等。解决这些痛点需技术、伦理与治理协同推进,以实现AI的真正赋能。

摘要:Apache Paimon 0.8.0作为新一代湖仓一体存储系统,具备ORC/Parquet列存、ACID事务和流批一体处理能力。其核心特性包括DeletionVector优化(查询提速50%)、PartialUpdate引擎和多引擎兼容扩展。通过FlinkCatalog配置可实现表创建与流式数据操作,生产实践中建议优化分区分桶策略、Compaction参数和内存管理。典型案例显示,Paim
本文详细介绍了YOLOv8目标检测算法的实现与应用。首先解析了YOLO的核心原理及v8版本的改进点,包括网络架构优化和损失函数改进。接着提供了完整的环境配置指南和模型训练流程,涵盖数据集准备、训练参数设置等关键环节。文章还重点阐述了推理部署优化技术,如TensorRT加速和量化部署,并分享了工业级部署实践中的模型剪枝、知识蒸馏等优化方法。最后展望了多模态检测、3D目标检测等未来发展方向。全文为构建

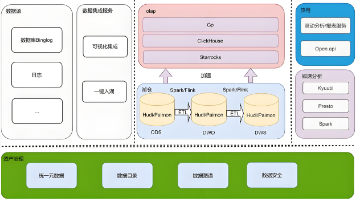
摘要: 数据标准平台与大模型的对接实现了数据治理的智能化跃迁。业务层面,大模型将数据标准制定、元数据管理等人工流程效率提升60%以上,并通过动态适配和智能应用释放数据价值,典型场景包括自动生成标准草案、语义化元数据填充等。技术架构上,通过“数据层-接口层-应用层”协同,确保数据安全与流程可控,关键技术涉及标准化数据供给、统一接口网关及提示词工程。落地挑战包括模型幻觉风险与数据合规,需通过多层校验和
本文对比分析了五种主流Web开发工具的核心特性与应用场景。Streamlit适合数据科学快速原型开发,Dash专攻企业级数据可视化,Flask是轻量级Web开发首选,FastAPI侧重高性能API服务,React则是前端交互标杆。选型建议:数据科学原型用Streamlit,企业仪表盘选Dash+FastAPI,小型项目用Flask,生产级API服务用FastAPI,复杂交互应用采用React+Fa

摘要:本文探讨数据标准平台与大模型融合的技术路径,从架构设计、数据治理、接口规范和安全机制四个维度提出解决方案。研究表明,通过分层架构实现多源数据接入、构建企业级指标字典确保语义一致性、采用标准化API接口和严格的安全防护措施,可显著提升系统性能。某制造企业实践案例显示,该方案使数据查询效率提升60倍,模型预测准确率达92%,有效推动企业智能化转型。未来需关注实时分析、自动化和多模态融合等发展趋势
摘要: 大模型本地化部署是企业实现数据安全、降本增效的关键路径。本文系统梳理了从硬件选型到性能调优的全流程技术要点:硬件方面需平衡算力与能效(如A100集群训练、Jetson边缘计算),构建三级存储体系;软件环境需优化依赖管理与容器化部署;工具链涵盖轻量级方案(llama.cpp)到企业级平台(千帆);性能调优涉及显存优化、算子融合等技术;安全防护通过TEE、水印等技术保障合规。未来趋势包括H20
