- @galoiszhou
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Python 的关键字(keywords)是语言保留的单词,具有特定语义,不能作为变量名或函数名使用。
特性for...infor...of遍历对象✅(包括继承属性)❌(除非实现 iterator)遍历数组⚠️(返回索引,顺序不保证)✅(返回值,顺序正确)返回内容键名(string)值(element)适用对象普通对象、数组、字符串等可迭代对象(数组、字符串、Set、Map、arguments等)
开启开发者模式,打开 USB 调试、USB 调试(安全设置),关闭监控 ADB 安装应用;纯净模式关闭增强防护,撤销 USB 授权重连电脑;电脑执行两条 adb 放行命令;adb install 带参数安装 Vature Spacewalker。
开启开发者模式,打开 USB 调试、USB 调试(安全设置),关闭监控 ADB 安装应用;纯净模式关闭增强防护,撤销 USB 授权重连电脑;电脑执行两条 adb 放行命令;adb install 带参数安装 Vature Spacewalker。
不会再显示 “On Your Network”。但如果你曾经修改过 host 设置(例如。这一行显示出来,则说明局域网访问被允许。),那就需要恢复或重新限制。能访问,就需要禁用这部分。,默认配置就已经是这样的;,不会监听局域网 IP。
React Hydration 错误是 Next.js SSR 应用中的常见问题。保证初始状态一致:服务器端和客户端首次渲染使用相同的值延迟读取客户端数据:在useEffect或中读取window等客户端 API合理使用警告抑制是最后手段,不能替代正确的实现通过遵循这些最佳实践,可以有效避免 hydration 错误,提供更好的用户体验。文档版本: 1.0最后更新: 2024相关文件。
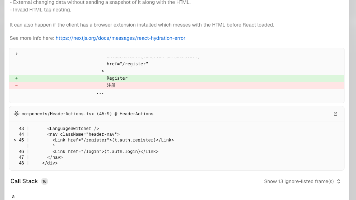
一条命令、两个参数,让依赖漏洞无处遁形。
深度学习(Deep Learning)深度学习在海量数据情况下的效果要比机器学习更为出色。多层神经网络模型。

如何在 ollama run qwen3 中关闭 think 模式在使用 ollama run qwen3 时,默认启用了 think 模式。如果你希望关闭这一模式,不同版本的 Ollama 有不同的设置方式。
AI 编程是最大增长极— Cursor、Claude Code、Copilot 引领潮流AI 视频大爆发— Sora、Hailuo、Kling 三强争霸DeepSeek 打破格局— 中国 AI 首次进入全球前二AI Agent 元年— 从对话工具转向自主完成任务ChatGPT 强势反弹— 4亿周活,GPT-4o + o1 推动增长手机端 AI 持续渗透— DeepSeek 手机端 5 天冲到 #1