




- @fyf2007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
关键词提取是信息检索和文本挖掘中的一项重要技术,它涉及从文本中识别和提取出最能代表文档内容的词语或短语。如下图所示,对于亚马逊上面的商品标题,在构建底层索引时,通常需要对标题做分词,提取里面核心词,用于构建倒排索引或者用于关键词匹配计算等。关键词提取技术可以通过多种方法实现,包括无监督学习和有监督学习的方法。首先,你需要定义一个LoRA模块,这个模块将被插入到BERT模型的特定层中。大语言模型,工

随着在纽约证券交易所上市的公司数量呈指数级增长,市场分析师、交易员和股东需要定期监控和评估大量公司的表现和战略转变,面临着重大挑战。提出了一种新颖的数据驱动方法,利用大型语言模型(LLMs)系统地分析和评估基于其SEC 10-K文件的公司表现。这些文件提供了公司财务表现和战略方向的详细年度报告,是评估公司健康状况各个方面(包括信心、环境可持续性、创新和劳动力管理)的丰富数据源。此外,介绍了一个自动

MAC笔记本安装Pytorch环境,深度学习代码开发

本文是一篇叙述性综述,旨在评估大型语言模型(LLMs)在临床摘要任务中的当前评估状态,并提出未来的方向,以解决专家人工评估的资源限制问题。本研究旨在全面回顾和实证评估多模态大型语言模型(MLLMs)和大型视觉模型(VLMs)在交通系统目标检测中的应用。研究首先提供了MLLMs在交通应用中的潜在优势的背景,并回顾了先前研究中当前MLLM技术的有效性和局限性。然后提供了交通应用中端到端目标检测的分类法

训练大型语言模型(LLM)使用开放领域的指令遵循数据取得了巨大的成功。然而,手动创建此类指令数据非常耗时且劳动密集。此外,人类可能难以产生高复杂度的指令。本文展示了一种利用LLM而非人类来创建具有不同复杂度级别的大量指令数据的方法。从一个初始指令集开始,我们使用提出的Evol-Instruct方法,逐步将它们重写为更复杂的指令。然后,我们混合所有生成的指令数据来微调LLaMA模型,最终模型被称为W

本研究系统探索了大语言模型(LLM)指令微调中不同类型指令数据的混合策略。将指令分为NLP任务、代码生成和通用对话三类,通过控制实验发现:1) NLP任务指令会提升专业性能但损害对话能力;2) 代码指令能同时增强代码和对话能力;3) 13B大模型比7B小模型更能有效融合多种指令类型。研究还揭示了最优混合比例(1.5:1)和数据规模"甜点"现象,为指令混合提供了实用指导。这些发现

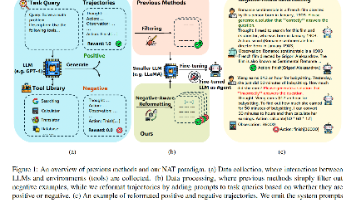
大型语言模型在作为智能体与外部环境(如搜索引擎等工具)交互方面已取得成功。然而,LLMs 在预训练或对齐阶段主要是针对语言生成而非工具使用进行优化的,这限制了它们作为智能体的有效性。为了解决这个问题,先前的工作通常先收集 LLM 与环境之间的交互轨迹,但仅使用那些成功完成任务的轨迹来微调较小的模型。这种做法使得微调数据变得稀缺,且获取数据既困难又昂贵。丢弃失败的轨迹也导致了数据和资源的大量浪费,并
关键词提取是信息检索和文本挖掘中的一项重要技术,它涉及从文本中识别和提取出最能代表文档内容的词语或短语。如下图所示,对于亚马逊上面的商品标题,在构建底层索引时,通常需要对标题做分词,提取里面核心词,用于构建倒排索引或者用于关键词匹配计算等。关键词提取技术可以通过多种方法实现,包括无监督学习和有监督学习的方法。首先,你需要定义一个LoRA模块,这个模块将被插入到BERT模型的特定层中。大语言模型,工
关键词提取是信息检索和文本挖掘中的一项重要技术,它涉及从文本中识别和提取出最能代表文档内容的词语或短语。如下图所示,对于亚马逊上面的商品标题,在构建底层索引时,通常需要对标题做分词,提取里面核心词,用于构建倒排索引或者用于关键词匹配计算等。关键词提取技术可以通过多种方法实现,包括无监督学习和有监督学习的方法。首先,你需要定义一个LoRA模块,这个模块将被插入到BERT模型的特定层中。大语言模型,工
随着GPT等大语言模型的陆续出现,人们逐步发现和接受了这样一个现实规律:增加数据量和模型参数往往是提升深度网络模型性能最简单粗暴的方法。目前主流的大模型参数量,通常都是千亿级别起步,并且还在不断持续地扩大。大型语言模型(LLM)的微调是为了使模型更好地适应特定的任务或领域。微调通常在模型的预训练阶段之后进行,预训练阶段模型在大量无标签数据上学习通用的语言特征,而微调阶段则使用特定任务的数据对模型进
