




- @fydw_715
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在两阶段检测中:RPN作为生成候选区域的关键组件,通过滑动窗口和锚点机制在特征图上生成高可能包含目标的候选区域。随后这些区域被进一步分类和调整,以提高检测精度。在单阶段检测中:没有RPN,直接在图像或特征图上进行预测。这减少了计算复杂度,但可能牺牲了一些细粒度的检测精度。Faster R-CNN:约100-200毫秒/图像YOLOv3:约22毫秒/图像Mask R-CNN:约200-300毫秒/图

随着大语言模型(LLM)参数规模突破千亿级,基于人类反馈的强化学习(RLHF)成为提升模型对齐能力的关键技术。OpenRLHF、verl、LLaMA-Factory和SWIFT作为开源社区的四大标杆框架,分别通过分布式架构、混合控制器、模块化设计和国产化适配,为70B级模型训练提供创新解决方案。随着RL4LM技术的持续突破,未来将出现更多跨框架融合方案,推动AGI安全对齐研究进入新阶段。开发者应根
services:api:MODE: api# 其他特定于 API 服务的环境变量db:redis:volumes:networks:- default作用:运行后端 API 服务,提供应用的核心功能。环境变量使用了共享环境变量。MODE: api:指定运行模式为 API 服务。依赖db(数据库服务)必须健康启动。redis(缓存)必须已启动。卷映射将主机的目录挂载到容器内的,用于存储用户文件。网
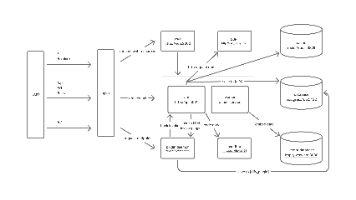
OpenRLHF与verl作为开源社区两大标杆框架,分别以Ray分布式架构和HybridFlow混合控制器为核心,为70B级模型训练提供创新解决方案。本文将深度解析二者的技术差异与实践价值。在AIME 2024数学推理基准测试中,基于verl的DAPO算法以Qwen-32B为基座模型取得50分,超越DeepSeek-R1-Zero 3.2个百分点。随着RL4LM(面向语言模型的强化学习)技术的持续
在强化学习中,智能体(Agent)通过与环境(Environment)交互,从环境中获取状态(State),并根据某种策略(Policy)选择动作(Action),执行后会得到环境的反馈,即下一个状态和奖励(Reward)。智能体的目标是通过学习,使得其在一系列行动中获得累积奖励最大化。
是一个非常实用的 Python 库,它的核心功能是从一个名为。假设我们正在开发一个需要连接数据库和调用天气 API 的应用。不会覆盖系统中已经存在的同名环境变量。的文件中读取键值对,并将它们加载到操作系统的。与 Flask 的集成非常顺畅,甚至可以说是。这意味着,在 Flask 项目中,你通常。文件排除在版本控制之外。创建一个 Python 文件(例如。命令会自动检测到它,并在启动应用前。文件不在
在两阶段检测中:RPN作为生成候选区域的关键组件,通过滑动窗口和锚点机制在特征图上生成高可能包含目标的候选区域。随后这些区域被进一步分类和调整,以提高检测精度。在单阶段检测中:没有RPN,直接在图像或特征图上进行预测。这减少了计算复杂度,但可能牺牲了一些细粒度的检测精度。Faster R-CNN:约100-200毫秒/图像YOLOv3:约22毫秒/图像Mask R-CNN:约200-300毫秒/图
大模型模型目录下的文件的作用分析

OpenRLHF与verl作为开源社区两大标杆框架,分别以Ray分布式架构和HybridFlow混合控制器为核心,为70B级模型训练提供创新解决方案。本文将深度解析二者的技术差异与实践价值。在AIME 2024数学推理基准测试中,基于verl的DAPO算法以Qwen-32B为基座模型取得50分,超越DeepSeek-R1-Zero 3.2个百分点。随着RL4LM(面向语言模型的强化学习)技术的持续
策略优化算法旨在通过优化策略,使智能体在与环境交互中获得最大累积奖励。价值函数方法(Value-based Methods):如Q学习,利用价值函数来指导策略选择。策略梯度方法(Policy Gradient Methods):直接对策略进行参数化,并通过梯度上升(或下降)优化策略参数。在LLM的训练中,由于模型的复杂性和动作空间的高维或连续性,策略梯度方法更为适用。通过将强化学习,特别是基于人类