- @fuleigang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
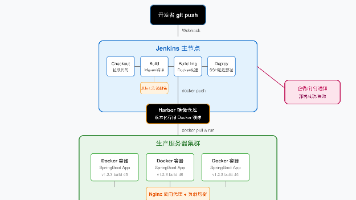
"content": "🎉 **部署成功**\\n\\n> 项目:my-springboot-app\\n> 版本:${IMAGE_TAG}\\n> 时间:${env.BUILD_TIME}\\n> 提交:${env.GIT_SHORT_SHA}"││Docker容器││Docker容器││Docker容器││。││拉代码││ Maven编译 ││Docker构建 ││ SSH远程部署││。
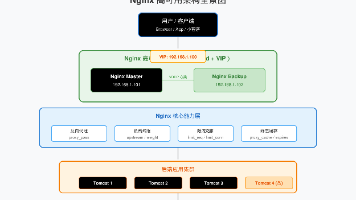
4. 调试用 `add_header X-Cache-Status $upstream_cache_status;2. 检查 Nginx 错误日志:`tail -f /var/log/nginx/error.log`- [ ] 安全响应头(X-Frame-Options、X-Content-Type-Options)1. `curl -v http://后端IP:端口/health` 直接访问后端
核心思想:把堆划分为多个大小相等的 Region(1MB~32MB),每个 Region 可以是 Eden/Survivor/Old/Humongous(大对象专用)。G1 跟踪每个 Region 的回收价值(回收获得的空间 + 回收所需时间),优先回收价值最高的 Region。| 对象头(Object Header)|mark word(8B,存储哈希码、GC年龄、锁信息)|1. 初始标记(In
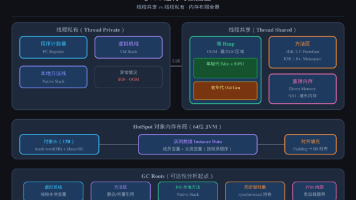
*并发问题**:漏标(漏标对象被当作垃圾)和多标(不该回收的对象被回收)。解决方案:**SATB(Snapshot-At-The-Beginning,G1使用)** 和 **增量更新(CMS使用)**。正确做法:用完 `remove()`。- `finally`:`try-catch-finally` 块中的代码,无论是否异常都执行(除非 System.exit())- ReadView:快照读时
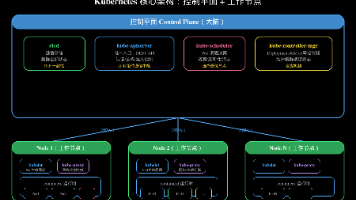
⚠️ **重要**:Secret 只是 Base64 编码,不是加密!**etcd**:高可用的键值存储,保存 K8s 集群所有状态数据(Pod定义、Service、ConfigMap等)。Kubernetes(K8s)是 Google 内部 Borg 系统的开源版本,是一个**容器编排平台**。核心理解:**Deployment 不直接管理 Pod,它通过 ReplicaSet 间接管理 Pod
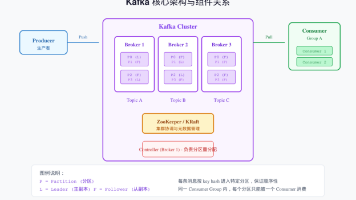
关键词:Kafka、消息队列、生产者、消费者、高吞吐、Exactly-Once、分区、副本。// 根据订单 ID 取模,保证同一订单消息进入同一分区(顺序性)order.getOrderId(),// key,用于分区路由。// 消费起始位置:earliest / latest / none。
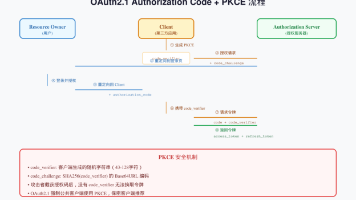
│←────────(6) 返回 access_token + refresh_token─│。│←────────(4) 重定向回 Client + auth_code ──────│。│──(5) 请求令牌 + code + code_verifier ────────→│。│──(3) 用户登录并授权────────────────────────────→│。│←────────(2) 重
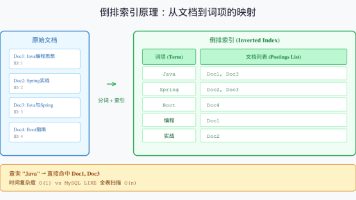
"refresh_interval": "30s",// 降低刷新频率,提升写入。{ "match": { "description": "旗舰" } }{ "term": { "category": "手机" } }单机 ES 轻松支撑 **千万级文档**,集群模式下可达 **百亿级**。ES 会把"苹果手机"拆成"苹果"、"手机"分别搜索,然后算相关性得分。{ "term": { "tags"
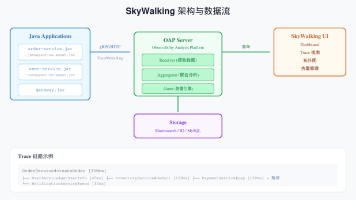
*SkyWalking = -javaagent 一行接入,Trace 视图一眼定位瓶颈,拓扑图一张看清依赖,告警规则一套守护生产。message: "服务 {name} 响应时间超过 1000ms,当前值: {value}ms"message: "服务 {name} 成功率低于 80%,当前值: {value}"关键词:SkyWalking、APM、链路追踪、分布式追踪、性能监控、Java Ag
[Kubernetes Ingress API文档](https://kubernetes.io/docs/concepts/services-networking/ingress/)- [Nginx Ingress Controller官方文档](https://kubernetes.github.io/ingress-nginx/)- [cert-manager官方文档](https://ce