




- @feng__shuai
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近deepseek属实又被炒了一波,作为做AI工程的从业者,有必要撸一遍vllm看看,熟悉一下目前llm的推理部署情况,核心看看page attention以及分布式的实现。
背景家里有个jetson-nano, 平日在外面使用的时候链接不到,正好自己有个固定IP的云服务器,所以就做了一个内网穿透,不过每次远程reboot后这哥们就失联了,需要回家才能连上开启frpc非常不方便,为此希望搞一个开机自启动。步骤cd /etc/init.d/touch mystartvim mystartchmod 777 mystartln -s /etc/init.d/mystart

bitmaskbitmask位遮罩比如打算用8位二进制表示可以任意组合的8个开关值则其对应bitmask为#defineSWITCH10x01#defineSWITCH20x02#defineSWITCH30x04#defineSWITCH40x08#defineSWITCH50x10#defineSWITCH60x20#defineSWITCH70x40#defi...
目前大模型的参数以及计算量越来越大,如果放在多卡上处理成为关键,这里简单记录一下每种并行策略的概念。目前大模型核心就是gemm、FFN(MLP)、attention, 所以下面的说明也以这三个算子作为说明。每个gpu上储存一份模型参数,通过切分batch来实现并行推理。
本文介绍了使用AWQ进行模型量化的实践指南。主要内容包括:1)环境配置,需安装特定版本transformer(4.51.3)并设置单卡运行;2)代码示例展示如何加载Qwen3-0.6B模型,配置4bit量化参数,并执行量化过程;3)注意事项指出目前AWQ支持的模型有限,且需处理版本兼容性问题。量化过程支持自定义校准数据集,最终生成量化模型可保存至指定路径。该方案适用于需要模型轻量化的应用场景,但需
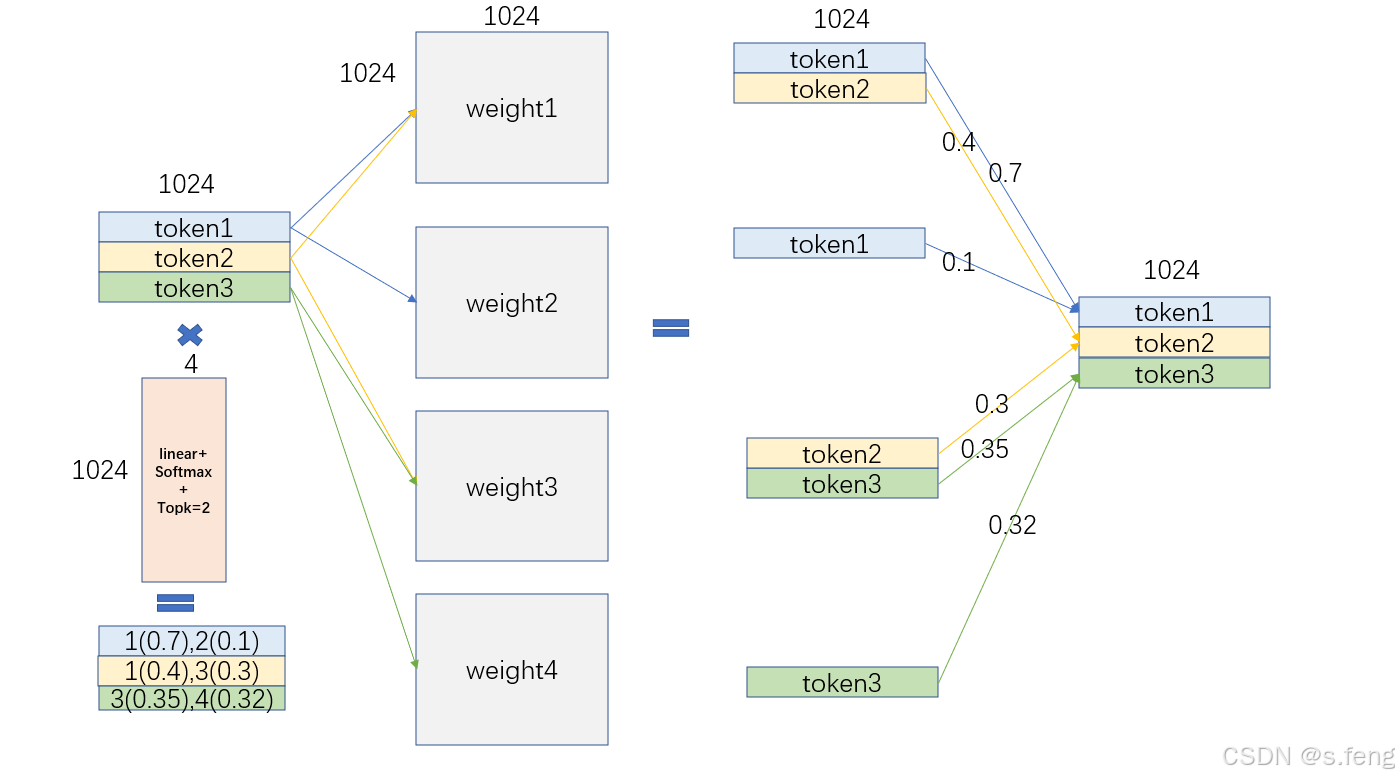
可以发现这三个矩阵的A矩阵尺寸不一样,不能用batched gemm,所以这里需要用grouped gemm来做,接下来可以看看为什么grouped gemm比batch gemm效果好。最近deepseek比较火,导致moe也比较热门,这里简单看看原理以及如何优化。1、首先每个token经过线性层和softmax选择自己的专家id。3、最后再根据不同专家的权重做一个合并。2、然后根据id选择不同
End-to-End Object Detection with Transformers[DETR]背景概述相关技术背景最近在做机器翻译的优化,接触的模型就是transformer, 为了提升性能,在cpu和GPU两个平台c++重新写了整个模型,所以对于机器翻译中transformer的原理细节还是有一定的理解,同时以前做文档图片检索对于图像领域的目标检测也研究颇深,看到最近各大公众号都在推送这
经常看CMakeLists.txt中有find_package和find_library,有时候没留意以为都一样,其实二者差距比较大,下面简单记录一下。find_package(NAME), 这段代码的本质就是在找一个NAME.cmake这个文件,一般在安装库的时候,会随行带一个文件NAME.cmake安装在系统的cmake文件里。https://zhuanlan.zhihu.com/p/6312
可以发现这三个矩阵的A矩阵尺寸不一样,不能用batched gemm,所以这里需要用grouped gemm来做,接下来可以看看为什么grouped gemm比batch gemm效果好。最近deepseek比较火,导致moe也比较热门,这里简单看看原理以及如何优化。1、首先每个token经过线性层和softmax选择自己的专家id。3、最后再根据不同专家的权重做一个合并。2、然后根据id选择不同
图片在进行放缩的时候,要进行插值,各个图处理软件的原理不一样,所以有时候发现像素值差距很大,下面是pytorch的原理展示,不大好解释,一图胜千言。Align_corners=TrueAlign_corners=False