- @falldeep
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenClaw 是一个开源的、自托管的 AI Agent 运行时框架,它将大语言模型(LLM)与真实世界的执行面(Execution Surfaces)连接起来:Shell 命令执行、文件系统访问、浏览器自动化、Docker 容器管理,以及超过 20 种第三方消息平台(WhatsApp、Telegram、Discord、Slack、飞书、企业微信等)。
OpenClaw 是一个开源的、自托管的 AI Agent 运行时框架,它将大语言模型(LLM)与真实世界的执行面(Execution Surfaces)连接起来:Shell 命令执行、文件系统访问、浏览器自动化、Docker 容器管理,以及超过 20 种第三方消息平台(WhatsApp、Telegram、Discord、Slack、飞书、企业微信等)。
要把inputs和labels重新view,-1为自适应inputs的格式为(seqlen, batchsize, inputsize)lables的格式为 (seqlen,1)seqlen其实就是循环次数。
dk\sqrt{d_k}dk除以dk\sqrt{d_k}dk就像是给注意力机制装了一个归一化调节器稳定方差:抵消维度dkd_kdk增大带来的数值膨胀。激活梯度:让 Softmax 避开饱和区,维持梯度的流动性。加速收敛:更稳定的数值分布让模型在训练初期更容易找到优化方向。
DPO 的出现将大模型的对齐从一个“强化学习问题”转化为了一个“有监督的分类问题”。它用极其简洁的数学手段实现了复杂的对齐目标,是目前工业界处理模型偏好学习的首选方案之一。
在大型语言模型(LLM)的后训练(Post-training)阶段,强化学习(RL)已成为实现复杂推理和人类价值观对齐的核心范式。LLM的RL过程本质上是一个在极其庞大且离散的状态-动作空间(State-Action Space,即Token的自回归生成)中进行策略优化的过程。本文从五个核心技术维度对当前LLM领域的RL方法进行分类,并盘点具有代表性的主流及最新算法。
当内存各分区中都无大小大于该作业的可用区时,判断空闲分区总和是否大于该作业的大小,若满足条件,则在紧凑后放入。设置内存总大小为1024KB,进入程序后有四种选项,插入作业请输入1,回收作业请输入0,紧凑请输入2, 查看内存信息请输入3,退出程序请输入4。插入一个名字为jincou的作业,大小为130KB,根据程序运行结果可以发现是经过了紧凑的,说明程序运行正确。此时已经产生了碎片,输入2,进行紧凑

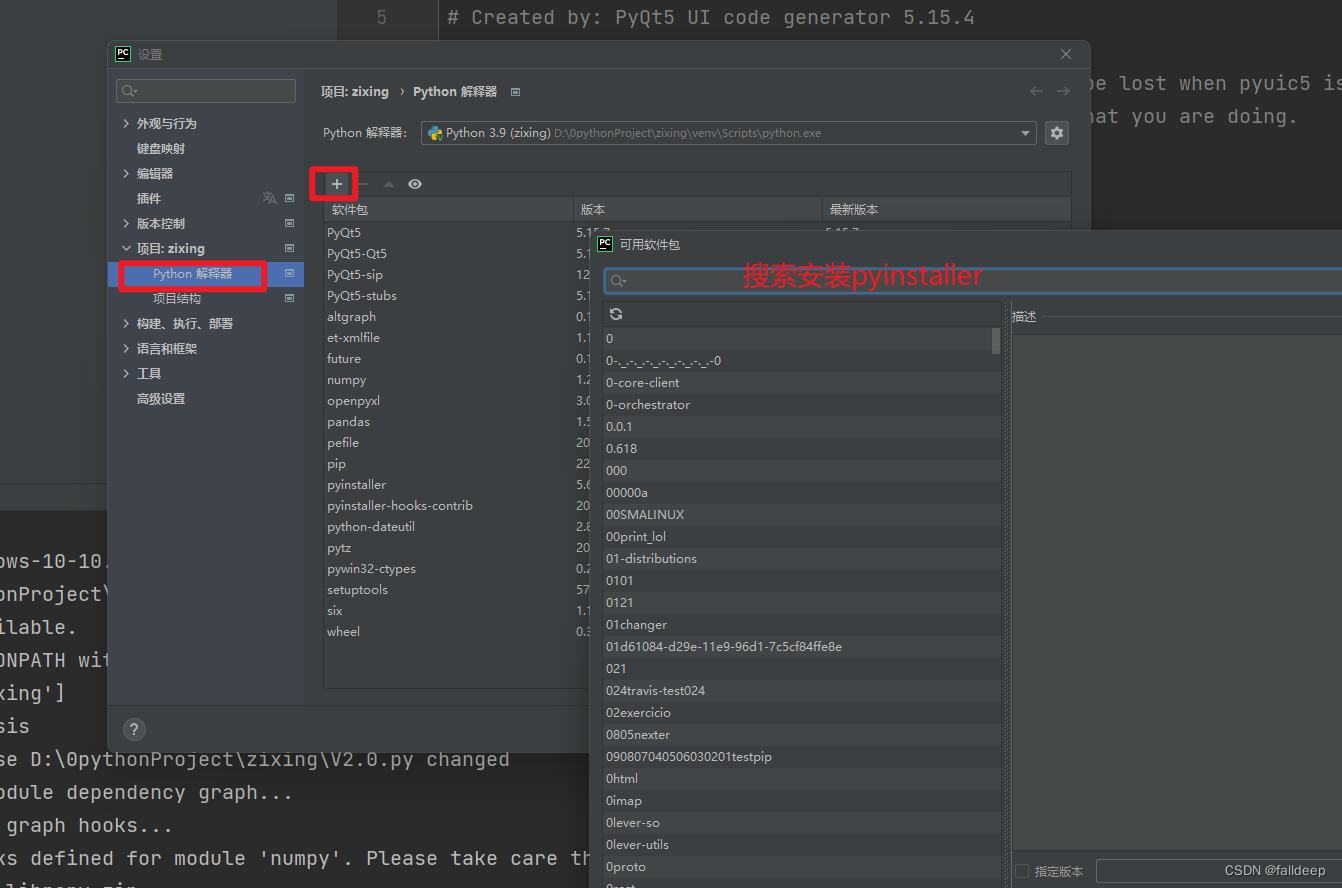
本人被pyinstaller折磨多次,遇上多次坑,终于总结出此条pyinstaller打包教程,小白无忧,帮你跳过所有坑。
要把inputs和labels重新view,-1为自适应inputs的格式为(seqlen, batchsize, inputsize)lables的格式为 (seqlen,1)seqlen其实就是循环次数。
代码】深度学习titanic(初学)Kaggle刘二作业第八课。