




- @doudou2weiwei
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2.奖励条件:如果碰到障碍物得到-1分,如果到达终点,得到10分。1.迷宫状态:起点已知,终点已知,障碍物随机分布。3.Q值更新规则与上一篇文章一致。4.动作选择仍旧采用贪心策略。

迷宫环境是定义好的,障碍物位置和空位置是已知的;

了解报文格式,能够发送和接收报文,实现CAN通信
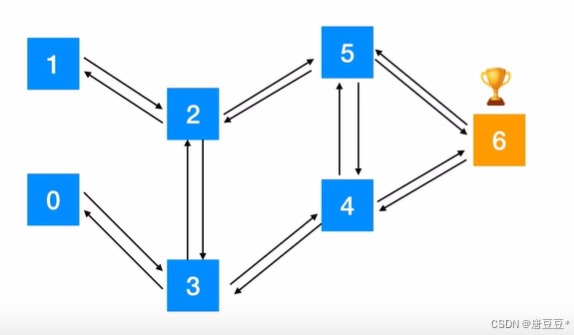
一、机器人多步决策过程用Qlearning算法思路:一、机器人多步决策过程用Qlearning算法思路:1.问题说明:机器人随机位于某个位置,需要到达位置6即为赢得游戏。2.奖励政策:机器人走迷宫一共有6个位置,6个位置的地图如下,给定奖惩规则为:不能通过给-1分,走到终点给100分。例如:如果机器人位于位置1,则该位置不能通过位置0(此时会给个-1分),走到了终点6就给一个100分。3.得到奖惩
以下程序为驱动电机正反转,由于我的驱动器采用的是双脉冲模式,即PUL为顺时针旋转IO口,DIR为逆时针旋转IO口,所以正反转只需要对不同引脚进行脉冲输出即可。writePWMVoltage(a,'D3',4)%在数字引脚3上产生4V的PWM信号,一般arduino uno的电压为0-5V。2.writePWMDutyCycle() 在PWM引脚上产生具有指定电压的PWM信号。

2.奖励条件:如果碰到障碍物得到-1分,如果到达终点,得到10分。1.迷宫状态:起点已知,终点已知,障碍物随机分布。3.Q值更新规则与上一篇文章一致。4.动作选择仍旧采用贪心策略。
一、机器人多步决策过程用Qlearning算法思路:一、机器人多步决策过程用Qlearning算法思路:1.问题说明:机器人随机位于某个位置,需要到达位置6即为赢得游戏。2.奖励政策:机器人走迷宫一共有6个位置,6个位置的地图如下,给定奖惩规则为:不能通过给-1分,走到终点给100分。例如:如果机器人位于位置1,则该位置不能通过位置0(此时会给个-1分),走到了终点6就给一个100分。3.得到奖惩
1.为什么要用梯度下降梯度的方向是函数上升最快的方向,沿着梯度方向对参数做更新,就可以使的目标函数增大。如图所示,对于函数y=f(x), 在A点的导数是大于零的,也就是增大x,f(x)也会增大。所以,我们沿着梯度方向前进,就可以找到目标函数的最大值。而我们的进行神经网络学习的时候,目标让预测值与真实值的误差之和最小,也就是是MSE(平均平方误差)最小:由于我们的优化目标是最小化目标函数(损失函数)

上述函数中的第一变量为方程组,第二个为待求变量。其中eqn表示方程组的表达式,var表示变量。用于求解方程组或者方程的符号解。一、solve函数的用途。2.建立方程组再调用。

参考:第八章 向量代数与空间解析几何——第四讲(空间直线) - 知乎 (zhihu.com)
